有一天,老板找到小明说:“公司都没有一个趁手的分布式任务调度系统,准备自研一个。组织经过慎重考察,决定把这个艰巨但光荣的任务交给你。你抓紧调研下,出个技术方案,尽快落地。要快~”
小明很懵,大大的眼睛盯着老板说:“我就是个curd boy,没做过,我不会呀”
老板说:“我会吗?美国佬会,苏联老大哥也会,可是他们不会白白的送给你!”
于是小明开始吭哧吭哧卷起来了。。。
概述
任务调度是指系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力由系统自动去执行任务。
各语言生态、各服务框架,都不同程度的提供了对单机或分布式的任务调度的支持,以便于实现日常业务需求中不同场景下定时处理逻辑,因此大家对任务调度的使用应该都比较熟悉。
但是如果我们将角色转换,像上文中的小明一样,从分布式任务调度使用者转变身份到分布式调度设计者、开发者,在不熟悉任务调度的相关概念、套路的情况下,黑盒的远观各个分布式任务调度系统,很自然的就会跟小明一样认为这东西是阳春白雪,门槛过高,过于神秘,我不会,我不配。
但其实当我们把相关概念拆解、套路理解、神秘感破除以后会发现,这个事情最后还是回归到最原始、质朴的CRUD。
架构
宏观架构
从宏观视角可以把任务调度划托管式的任务调度和触发式的任务调度。
托管式任务调度
所谓的托管式,就是任务调度系统一站式托管了任务的触发和任务的运行。用户需要提交任务触发相关的元信息和任务执行需要的全套代码和数据,后续的任务调度即可完全在调度平台闭环、自治。
该类型的任务调度平台,除了需要实现高可用的任务触发能力外,还需要有完善的计算资源管理、调度的能力。当然,计算资源的管理、调度能力可以借助独立的资源管理平台来实现,比如Mesos,YARN,K8s等。
该架构呈现给用户的使用界面更多的类似于一个分布式计算平台,将用户提交代码和数据定时、透明的分派到各个计算节点执行。以java技术栈为例,用户提交一个jar包并定义触发周期和参数,后续的jvm的启动、代码执行、生命周期管理等动作全部由平台托管。
业界典型的实现有elastic-job-cloud,然后因为实现完分布式资源编排、调度以后,加一个定时任务调度能力也就是捎带手的事情,所以K8s也支持cron任务,某种意义上也可以划分到这一类中。
该架构下的任务调度系统,将定时任务逻辑和微服务中的业务逻辑切分开了。对于B/C端OLTP业务开发的场景并不友好。因为B/C端的定时任务逻辑往往需要就近在业务服务进程中执行,一方面可以复用大量既有的业务处理逻辑,另一方面服务的内聚性更好,方便迭代和维护。
触发式任务调度
所谓的触发式,就是任务调度系统只负责定时产生一次调度事件,然后通过适配多种协议、多种资源将该调度事件下发、通知到各种类型的外部系统、服务中,而具体的业务逻辑的执行由外部系统、服务自治。
相对于托管式的任务调度,该架构下的任务调度系统职责更单一更纯粹,系统复杂度和稳定性都会有更好的表现。同时不挑语言、不挑框架,在跨平台适配上的成本也更低。
该架构在OLTP场景下使用较为广泛,定时任务逻辑代码和在线请求处理逻辑代码放在一起,方便复用和维护,任务代码和在线请求处理代码的一致性更好,使用的割裂感也更低。
同时也便于日常进行的统一的稳定性监控。大家比较熟知的分布式quartz、xxl-job、elastic-job-lite都可以划分到该架构类型中。
总结
显然,在OLTP业务场景下,触发式的任务调度系统更具潜力和市场。同时触发式任务调度也是托管式任务调度的核心和基础,有了一个成熟、稳定的调度、触发服务,只要再适配一个计算资源管理系统,托管式的任务调度系统也就出来了。
所以后续的论述我们就聚焦在触发式任务调度系统。
微观架构
触发式任务调度架构的典型组成部分是服务端(调度端)和集成了SDK的客户端(执行端)。不同的微观实现会在两端各有侧重。
有的实现会弱化调度端甚至去调度端,将调度逻辑集中在客户端,我们可以称其为胖客户端模式。典型的比如分布式quartz、elastic-job-lite。
有点实现会弱化执行端,将调度逻辑集中在服务端,我们可以称其为瘦客户端模式。典型的比如xxl-job。
同时业界也有混合上述两种模式的实现但是并不普遍,笔者个人觉得这种反而把事情搞复杂了,典型的比如power-job。
胖客户端模式
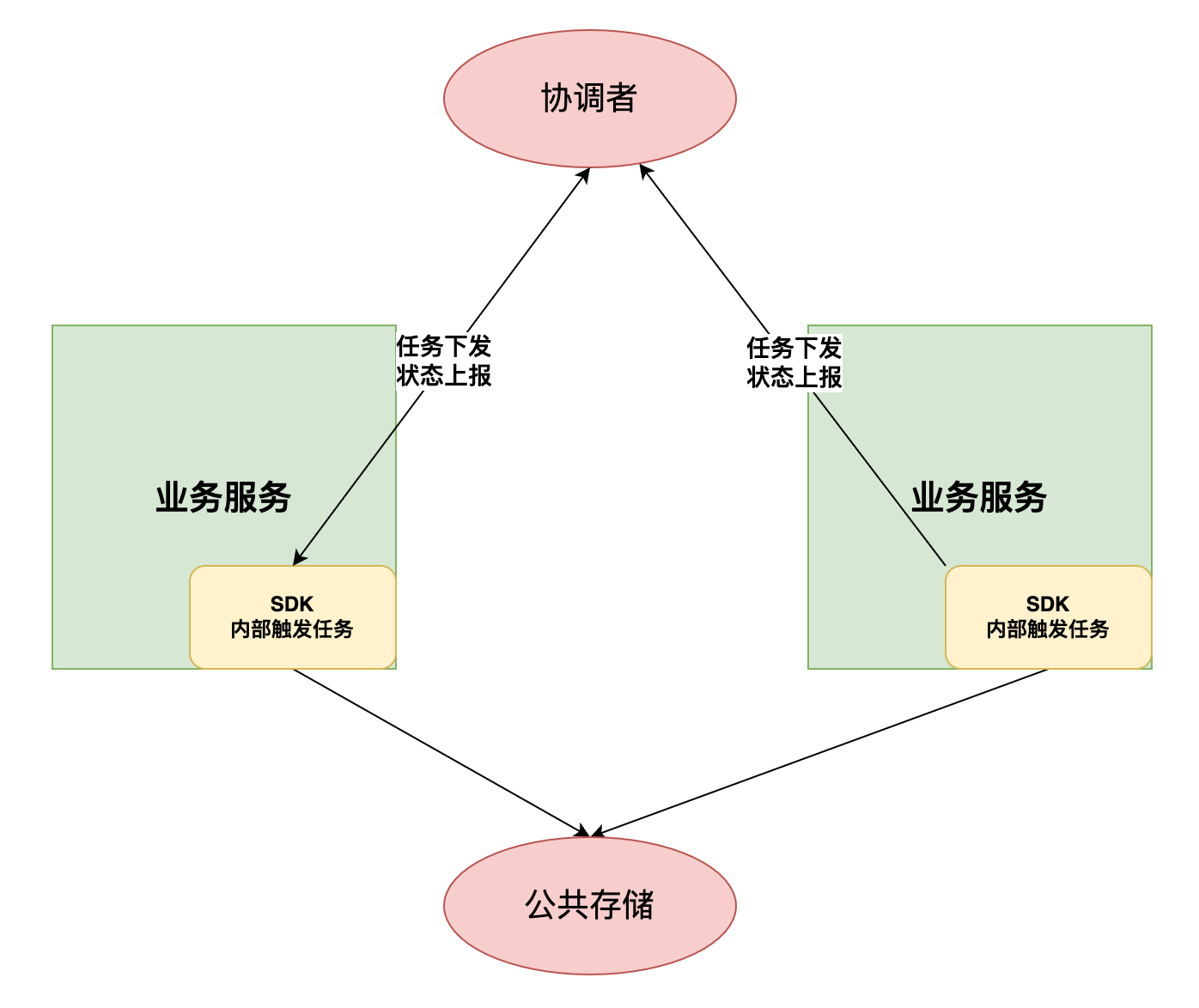
所谓的胖客户单模式是指,核心的调度、触发逻辑通过SDK集成的方式和任务逻辑在一个进程中运行。接入了SDK的业务服务集群中的每个节点都对等的触发任务。任务下发不需要经过网络,因为都在一个进程里。
该模式下,任务触发存在竞争,为避免冲突,需要一个外部的协调者来仲裁。同时SDK需要共享同一份任务信息元数据,所以需要读写一个公共存储组件。一般来说,可以由某一个外部组件同时充当该两种角色,比如可以Zookeeper、RMDB。
分布式Quartz使用关系数据库比如Mysql的表锁或行锁来进行分布式调度的协调和仲裁,同时也利用关系数据库来共享任务元信息。类似的,elastic-job-lite选用的是Zookeeper。
该模式下一般会被笼统的称为去中心化的任务调度,因为整个架构中没有中心化的、单点的调度端。但是分析可知,该模式并没有去中心,只不过中心化的组件是通用的、调度逻辑无关的组件比如Zookeeper。
该模式的优点有:
- 故障半径小:各个业务服务的任务调度在各自业务集群内自治,不会互相挤兑。
- 自闭环:考虑到RMDB或者Zookeeper是广泛使用的通用组件,即便不使用任务调度也可能因为别的需求在业务服务中被引入、使用。所以该模式下可以在不新增外部组件依赖的前提下实现分布式任务调度。
但是,该模式同时也有如下缺点:
- 任务调度能力的演进受限:将重量级的调度逻辑封装在SDK中交付出去后,后续的演进难以推广落地,功能迭代和缺陷修复都需要广泛的推动升级
- 难以跨平台、跨语言:因为SDK里的逻辑很重,所以每个平台、每个语言的适配都需要付出巨大的成本
- 任务调度变更管控受限:由于缺少中心化的调度端,导致任务元信息散落在各个RMDB或者Zookeeper中,难以进行相关的元信息收拢、管控。
- 任务调度观测性受限:同样由于散落各处的任务信息和调度信息,难以平台化的统一收拢、关联任务调度过程中的观测性数据。
瘦客户端模式
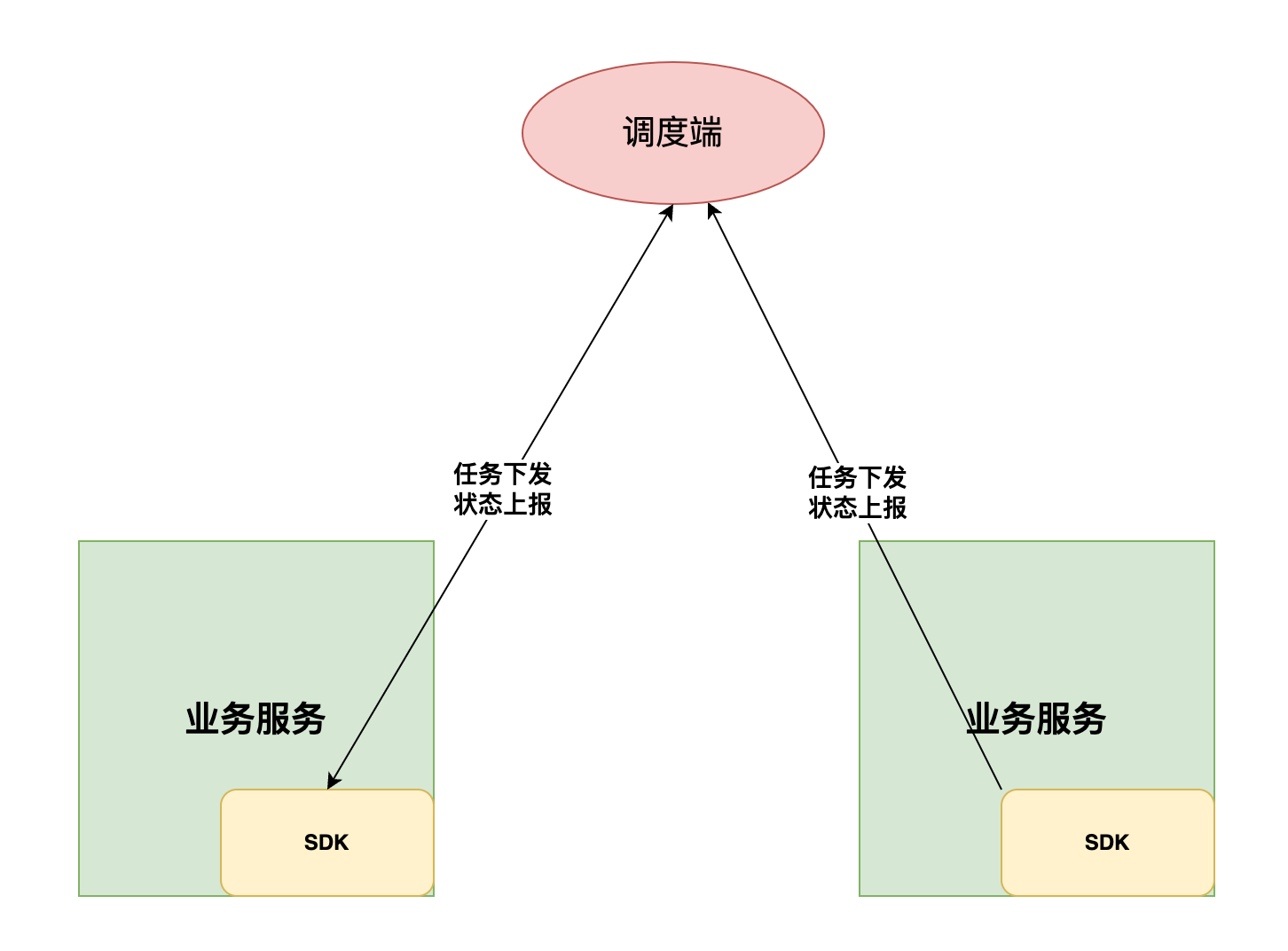
瘦客户端模式是指,任务调度、触发的逻辑收拢到独立服务中,独立的迭代、演进。业务服务中可以集成SDK方便开箱即用的接入任务调度能力,但是也可以直接暴露公共协议(http、dubbo、grpc)接口供调度端调用、触发任务。 该模式下的SDK代码很薄很稳定,跨平台适配的成本很低,核心能力主要有:
- 监听网络端口,等待任务执行指令下发
- 任务逻辑执行完成后,上报执行的状态或结果。
该模式下,整个任务调度过程由中心化的服务端主导,因此可以实现强有力的管控和完整的调度观测性数据收集。同时调度端和执行端的代码解耦,独立演进,组件架构和组织架构也是匹配的。
总结
综合上述,如果是建设企业级的大量业务服务使用的分布式任务调度平台,考虑到统一架构演进、跨平台/语言调度、变更管控、调度追溯等因素,瘦客户端模式是更适合的选择。
调度
如上述,我们确定了分布式任务调度的架构,现在我们向前一步进行核心调度逻辑的研究、细化。
在Java生态里,一提到任务调度,就绕不过Quartz。你在gayhub上搜任务调度或job,语言选java,按star数量降序clone十个项目下来看,九个里面任务调度、触发kernel还是Quartz库,包括elastic-job。
如果将调度、触发的核心委托给Quartz,很大程度上可以提高开发的效率,剩下的工作就是进行分布式集群的整合、外围管控功能的开发了。但是将核心功能委托到黑盒的三方库的合理性还是有待商榷的。
一方面,Quartz也并没有什么只有它能实现的黑科技,或者换句话说,咱们不用Quartz,也可以自己实现一个灵活的、易于定制的任务调度、触发kernel。
而且由于Quartz诞生于2001年,那会最新的jdk版本还是1.3,所以Quartz项目的代码在笔者看来就很老派或者啥的吧,受限于当时的jdk版本特性少,很多代码写的贼绕,看麻了 T_T。
另一方面,自己实现核心的调度、触发逻辑,也便于从底层开始进行分布式的定制、优化。Quartz内置的分布式方案的性能会有瓶颈所以我们不能直接用,但是如果从外围来将单机Quartz组合成分布式集群又有点隔靴搔痒,也不便于后续核心能力的优化、演进。
总之,与其引入一个黑盒的三方库,作为一个有志青年,我们应该立志于从底层核心开始自研,但是Quartz作为该领域久经考验的老牌实现,也有如下几点值得我们参考和学习的点:
- 如何实现单机的任务触发的?
- 如何实现Cron任务的?
熟悉一个新领域的事物,突然猛地一下子钻进源码,陷入细节不是一个高效的方式。所以笔者不会着手进行Quartz源码解析。还是照着我们自己的思路、节奏一步步来理解整个任务调度的脉络。
在实现分布式任务调度之前,我们需要先研究明白,单机的任务调度是怎么玩的?因为分布式调度本质上是单机调度的集群组合。
其实核心就一句话:轮询待执行的任务列表,对比任务待执行时间,到时间了就触发任务回调,并更新下一次任务调度时间。围绕这个核心逻辑,进行一步一步的演化,最终会实现Quartz相同的能力。
数据结构
首先我们对齐一下任务调度相关的核心数据结构。
任务回调
public interface JobHandler {
/**
* 在指定时间触发任务后,会调用该方法
* 该方法用于实现任务的具体业务逻辑
*/
void execute();
}
这是一个会被业务代码耦合的接口,具体的实现里,为了实现更多定制化的能力可能还会有其他用于进行特性控制的方法,但是核心的方法就上面一个就够了。
定时策略
public interface NextTimeCalculator {
/**
* 指定任务开始时间或上次触发、执行时间
* 根据不同策略计算出任务的下次执行时间
*
* @param preTime 秒级时间戳
* @return 秒级时间戳
*/
long nextTime(long preTime);
}
这个接口一般不会被业务代码耦合,更多的是系统内部的策略模式的抽象。系统内部会预置多种NextTimeCalculator比如Cron、FixRate、FixTime等。暴露到使用者的可能就是定时类型+计算参数两个配置了。
任务定义
public class JobDefinition {
/**
* 任务标识
*/
private String jobName;
/**
* 下次执行时间
*/
private long nextTime;
/**
* 时间计算器
*/
private NextTimeCalculator calculator;
/**
* 任务回调
*/
private JobHandler handler;
}
上述任务调度系统内部核心的任务定义,具体的实现还会维护更多的信息,但是核心的字段就只需要这么多了。
使用门面
public interface JobManager {
void start();
void addJob(JobDefinition job);
}
添加job后,调用start方法,即可开启任务调度、触发了。
调度、触发逻辑
对齐上述数据结构后,核心的调度、触发代码都在JobManager中,我们开始对其进行代码实现和演进。
版本1:最直观的版本
public class JobManagerImplV1 implements JobManager, Runnable {
private final Set<JobDefinition> definitions = Sets.newHashSet();
private volatile boolean running = false;
@Override
public void start() {
running = true;
new Thread(this, "JobScheduler").start();
}
@Override
public void addJob(JobDefinition job) {
if (running) {
throw new IllegalStateException();
}
long nextTime = job.getNextTime();
if (nextTime <= 0) {
nextTime = Instant.now().getEpochSecond();
}
definitions.add(job);
}
@Override
public void run() {
while (running) {
// 当前时间
long now = Instant.now().getEpochSecond();
// 遍历所有任务定义
for (JobDefinition definition : definitions) {
long nextTime = definition.getNextTime();
// 如果任务下次执行时间到了,就开始执行
if (nextTime <= now) {
JobHandler handler = definition.getHandler();
handler.execute();
// 重新计算下次执行时间
NextTimeCalculator calculator = definition.getCalculator();
long newTime = calculator.nextTime(nextTime);
definition.setNextTime(newTime);
}
}
}
}
}
如上图,就是按上述核心原理逐字逐句、直观简单的实现。这个粗糙的版本肯定不是可用版本,但是已经能够说明问题了,接下来我们继续演进。
版本2:线程休眠
版本1的实现有如下几个问题:
- 调度线程无脑的死循环遍历、判断是不是有任务要执行了,在任务执行密度较小的场景下,会存在大量无意义的CPU消耗。
- 任务调度、触发和任务执行没有隔离开,放在一个线程中。如果任务执行的逻辑中存在阻塞,或导致后续的任务无法按时调度、触发。
第2个问题好解决,加个任务执行线程池隔离开就好了。第1个问题是需要花费笔墨讨论下的。
为什么调度线程需要无脑的死循环遍历、轮询整个任务列表呢?根本原因是因为任务调度线程无法预期最近任务会在什么时候执行,因此只能一刻不停的一个任务一个任务的判断,避免产生调度、触发延迟。
所以我们需要维护一个最近的待执行任务的时间,这样在时间到来之前,调度线程可以休眠阻塞,既可以避免无意义的CPU消耗,同时也能保证任务被准时触发。
public class JobManagerImplV2 implements JobManager, Runnable {
private final Set<JobDefinition> definitions = Sets.newHashSet();
private volatile boolean running = false;
private long latestNextTime = Long.MAX_VALUE;
private Executor executor;
@Override
public void start() {
executor = Executors.newFixedThreadPool(50, r -> new Thread(r, "JobExecutor"));
running = true;
new Thread(this, "JobScheduler").start();
}
@Override
public void addJob(JobDefinition job) {
if (running) {
throw new IllegalStateException();
}
long nextTime = job.getNextTime();
if (nextTime <= 0) {
nextTime = Instant.now().getEpochSecond();
}
//添加任务时,维护好最近的一个任务待执行的时间
latestNextTime = Math.min(latestNextTime, nextTime);
definitions.add(job);
}
@Override
public void run() {
while (running) {
long now = Instant.now().getEpochSecond();
//遍历所有任务定义
for (JobDefinition definition : definitions) {
//当前时间
long nextTime = definition.getNextTime();
//如果任务下次执行时间到了,就开始执行
if (nextTime <= now) {
JobHandler handler = definition.getHandler();
executor.execute(handler::execute);
//重新计算下次执行时间
NextTimeCalculator calculator = definition.getCalculator();
long newTime = calculator.nextTime(nextTime);
definition.setNextTime(newTime);
//更新任务下次执行时间时,维护好最近的一个任务待执行的时间
latestNextTime = Math.min(latestNextTime, newTime);
}
}
try {
//每轮任务触发后,开始计算当前时间和最近的任务下次执行时间的间隔
//休眠到指定时间,开始进行下一轮调度
TimeUnit.SECONDS.sleep(Math.max(latestNextTime - now, 0));
} catch (InterruptedException ignore) {
}
}
}
}
版本3:优先级队列
版本2解决了忙轮询导致的CPU负载高的问题,但是每一轮遍历都需要遍历整个任务列表。
一方面大量任务可能是在很久以后执行,不需要每次都判断是否需要执行;另一方面,如果任务列表数据量很大,这种无差别的遍历会产生大量无意义的CPU消耗和调度、触发延迟。
这个问题该如何解决?我们需要明确,为什么每次都需要遍历所有任务。
本质原因是因为任务列表是无序的。因为任务列表无序,所以我们无法预期下一个待执行的任务在列表中的位置。所以只能无差别、无脑的全部遍历一遍,避免遗漏。
所以我们只需要每次更新完任务下次执行时间以后,按nextTime对任务列表做一下排序就可以解决这个问题了。
在任务调度场景下,我们无需进行列表的全局排序,只要能高效的从排序列表中取nextTime最小的任务定义即可。
这种算极值或者TopK的排序数据结构,比较典型的就是堆。在任务调度的场景下,使用小顶对即可满足要求。
堆就是用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。 堆的常用方法:
- 构建优先队列
- 支持堆排序
- 快速找出一个集合中的最小值(或者最大值)
- 在朋友面前装逼
堆属性 堆分为两种:最大堆和最小堆,两者的差别在于节点的排序方式。
在最大堆中,父节点的值比每一个子节点的值都要大。在最小堆中,父节点的值比每一个子节点的值都要小。这就是所谓的“堆属性”,并且这个属性对堆中的每一个节点都成立。
JDK标准库自带了优先级队列的实现,那我们按拿来主义使用即可。
public class JobManagerImplV3 implements JobManager, Runnable {
/**
* 按任务下次执行时间排序的优先级队列
*/
private final PriorityQueue<JobDefinition> definitions = new PriorityQueue<>(Comparator.comparingLong(JobDefinition::getNextTime));
private volatile boolean running = false;
private Executor executor;
@Override
public void start() {
executor = Executors.newFixedThreadPool(50, r -> new Thread(r, "JobExecutor"));
running = true;
new Thread(this, "JobScheduler").start();
}
@Override
public void addJob(JobDefinition job) {
if (running) {
throw new IllegalStateException();
}
long nextTime = job.getNextTime();
if (nextTime <= 0) {
nextTime = Instant.now().getEpochSecond();
}
//将任务定义添加到优先级队列
definitions.add(job);
}
@Override
public void run() {
while (running) {
long now = Instant.now().getEpochSecond();
while (true) {
JobDefinition definition = definitions.poll();
assert definition != null;
//当前时间
long nextTime = definition.getNextTime();
//如果任务下次执行时间到了,就开始执行
if (nextTime <= now) {
JobHandler handler = definition.getHandler();
executor.execute(handler::execute);
//重新计算下次执行时间
NextTimeCalculator calculator = definition.getCalculator();
long newTime = calculator.nextTime(nextTime);
definition.setNextTime(newTime);
//更新下次执行时间后,重新添加到任务队列
definitions.add(definition);
} else {
//执行到此处,说明下次执行时间小于等于当前时间的任务已经遍历完了
//后面的任务无需遍历,等待下一轮遍历即可
break;
}
}
//从任务队列中取出(peek)顶上的、下次执行时间最小也就是最近待执行的任务
JobDefinition peek = definitions.peek();
assert peek != null;
long nextTime = peek.getNextTime();
//每轮任务触发后,开始计算当前时间和最近的任务下次执行时间的间隔
try {
//休眠到指定时间,开始进行下一轮调度
TimeUnit.SECONDS.sleep(Math.max(nextTime - now, 0));
} catch (InterruptedException ignore) {
}
}
}
}
总结
经过上述3个版本的演进,已经呈现出了一个粗糙但是完整的单机任务调度、触发核心流程。Quartz内部的单机任务调度、触发的核心流程也就是这样,大差不差。
一路走下来,在单机任务调度的基础上实现分布式任务调度的思路或方向就一目了然了。
- 把版本3中的优先级列表,替换成一个外置的共享存储,让分布式任务调度集群的各个调度节点可以共享数据。
所谓的优先级列表,在RMDB里其实就是
select * from t order by next_time desc,在Redis里就是ZSet,或者其他的存储组件,都可以进行类似的映射和转换。 - 上述分布式集群场景下,多个调度节点读写一份共享存储,竞争读写会产生数据覆盖等问题 这也没啥,加个分布式锁,让调度集群里的节点串行读写就好了。Redis、Zookeeper或者数据库的行锁表锁都可以。
- 按上述全局锁串行的读写共享存储的话,性能会有问题吧? 那就分片,找个公共的存储让调度集群的节点注册、登记自己的信息。这样调度集群里的每个节点都能感知到当前调度集群有几个节点,按约定的算法排序算出来自己归属的序号。然后对任务id取余分片认领任务、处理任务就好了。
- 每次都等到任务要执行了才唤醒线程,是不是会产生调度延迟? 没错,那就提前一点时间唤醒,问题不大。
CRON表达式
如上述,NextTimeCalculator是对任务定时策略的抽象。常见的有FixRate、FixTime、Cron。
对于前两种类型的定时策略,大家指定不陌生,轻轻松松就可以实现。
public class FixRateCalculator implements NextTimeCalculator {
private final long intervalSec;
/**
* 指定时间间隔执行
*
* @param intervalSec
*/
public FixRateCalculator(long intervalSec) {
this.intervalSec = intervalSec;
}
@Override
public long nextTime(long preTime) {
return preTime + intervalSec;
}
}
public class FixTimeCalculator implements NextTimeCalculator {
private final long fixTimeTsSec;
/**
* 指定绝度时间点执行
*
* @param time
*/
public FixTimeCalculator(LocalDateTime time) {
fixTimeTsSec = time.atZone(ZoneId.systemDefault()).toEpochSecond();
}
@Override
public long nextTime(long preTime) {
if (preTime >= fixTimeTsSec) {
return Long.MAX_VALUE;
}
return fixTimeTsSec;
}
}
但是对于Cron类型任务执行时间计算,大家可能就比较陌生了。但是它其实也很简单。
Cron表达式是什么
Cron表达式是一种DSL,领域特定语言。
所谓领域特定语言,就是针对特定领域、场景,设计的具有特定便捷语法的语言。往往被软件设计者用来暴露易用且灵活的用户使用界面。
此处的使用界面不是指GUI,而是指API等软件层面的耦合界面
Cron表达式就是针对任务调度场景设计的DSL,它可以便捷、直观的表达出任务可以被调度的时间特征。基于这些特征,任务调度系统就可以通过解析、搜索得到任务允许执行的时间点。
Cron表达式中空格分割的多个字段,分别对应现实自然时间中的年月日、时分秒、星期。用户可以在各个字段指定特征,简单、自然、灵活。
例如:
**/5 ** * * * ?表达的意思是,只要时间点的秒数可以被5整除,那这个时间点要执行任务。
*1 \* * \* * ?*表达的意思是,只要时间点的秒数是1,那这个时间点要执行任务。
** 1 \* 1 \* ?*表达的意思是,只要时间点的分钟数是1且日期是1,那这个时间点要执行任务
任务调度系统通过枚举一段时间内的所有时间点并和CRON表达式进行比对,即可得到任务可以执行的时间点,从而完成定时调度。
Cron表达式怎么使用
Cron的使用分两步:
- 【解析】编写语法解析代码,将Cron表达式中用结构化文本表达的时间特征转换为一个Predicte(断言)纯函数,如下为示意:
public interface CronTimePredicate {
/**
* 根据指定的CRON表达式,解析得到一个对应的CronTimePredicate
*
* @param cronExpr
* @return
*/
static CronTimePredicate parse(String cronExpr) {
return null;
}
/**
* 输入某个带时区的时间点
* 根据CRON表达式判定该时间点是否满足特征
* 满足特征的时间点即为任务下次执行时间
*
* @param time
* @return
*/
boolean test(ZonedDateTime time);
}
- 【搜索】从指定时间开始枚举时间点,交由上述CronTimePredicate判定是否满足Cron表达式的特征,满足条件的时间点即为任务下次执行时间
public class CronTimeCalculatorV1 implements NextTimeCalculator {
private CronTimePredicate predicate;
/**
* 指定CRON表达式
*
* @param cron
*/
public CronTimeCalculator(String cron) {
predicate = CronTimePredicate.parse(cron);
}
@Override
public long nextTime(long preTime) {
ZonedDateTime start = Instant.ofEpochSecond(preTime).atZone(ZoneId.systemDefault());
while (true) {
start = start.plusSeconds(1);
boolean result = predicate.test(start);
if (result) {
return start.toEpochSecond();
}
}
}
}
因为Quartz Cron表达式支持秒维度的特征,所以该简单示例实现以秒为步长自增进行时间点枚遍历、搜索,整体性能很差。
完整、健壮的实现会分析Cron表达式的特征,动态设置时间点自增步长,提高时间搜索效率。
上面两个步骤,本质上其实就是根据时间特征搜索合适的、匹配的时间点。
上述可知,Cron表达式是一种公共DSL,所谓的公共DSL,是说它不会因为任务调度系统的具体实现不同而有定制的变化,它是独立的、稳定的。既没有定制的空间,也没有定制的必要。
当前能表达的特征已经够用了,没必要重新设计、实现一个语法 ,增加用户上手难度。
Cron表达式源自linux crontab,本身只支持分钟级精度。Quartz对Cron做了定制、拓展,增加的秒维度的特征限定
因为它公共且稳定,所以上述Cron表达式解析、搜索的代码都有人写好了,也不用我们自己写~所以笔者才说它简单。Spring里有,Quartz里有,还有其他的独立的三方库也提供了Cron解析和时间搜索的功能。
比如:
<dependency>
<groupId>com.cronutils</groupId>
<artifactId>cron-utils</artifactId>
<version>9.2.0</version>
</dependency>
那我们就用这个来实现一个Cron类型的NextTimeCalculator吧。
public class CronTimeCalculatorV2 implements NextTimeCalculator {
private static final CronParser quartzCronParser = new CronParser(CronDefinitionBuilder.instanceDefinitionFor(CronType.QUARTZ));
private ExecutionTime executionTime;
/**
* 指定CRON表达式
*
* @param cronExpr
*/
public CronTimeCalculatorV2(String cronExpr) {
if (StringUtils.isBlank(cronExpr)) {
throw new IllegalArgumentException("cronExpr is blank");
}
Cron cron = quartzCronParser.parse(cronExpr);
executionTime = ExecutionTime.forCron(cron);
}
@Override
public long nextTime(long preTime) {
if (preTime == Long.MAX_VALUE) {
return Long.MAX_VALUE;
}
Instant instant = Instant.ofEpochSecond(preTime);
ZonedDateTime preZonedDateTime = ZonedDateTime.ofInstant(instant, ZoneId.systemDefault());
Optional<ZonedDateTime> nextTimeOpt = executionTime.nextExecution(preZonedDateTime);
return nextTimeOpt.map(ChronoZonedDateTime::toEpochSecond).orElse(Long.MAX_VALUE);
}
}
总结
总而言之,Cron表达式这个东西和任务调度强相关,要做一个分布式任务调度系统避不开它,但是它其实也很简单。
总结
至此,笔者已经介绍完任务调度相关的核心概念和原理。
当然,上述的内容还不足以完整、健壮的实现一个分布式任务调度系统,需要解决、处理的问题还有很多,但是这些需要解决和处理的问题已经都不是任务调度系统特有的问题了,整个事情已经回归到了系统设计领域的公共基础知识。
