Unicode
为实现跨平台信息交换、展示设计的统一编码,目的是为世界上所有的字符分配一个唯一的数字编号。
编号有个别名叫【码点】,也就是说码点就是一个数字。
编号的空间或者说容量有17*65536(111.4万),可以容纳一百万个字符。
整个空间按种类、使用频率分为17组,每组2^16个字符(65536)
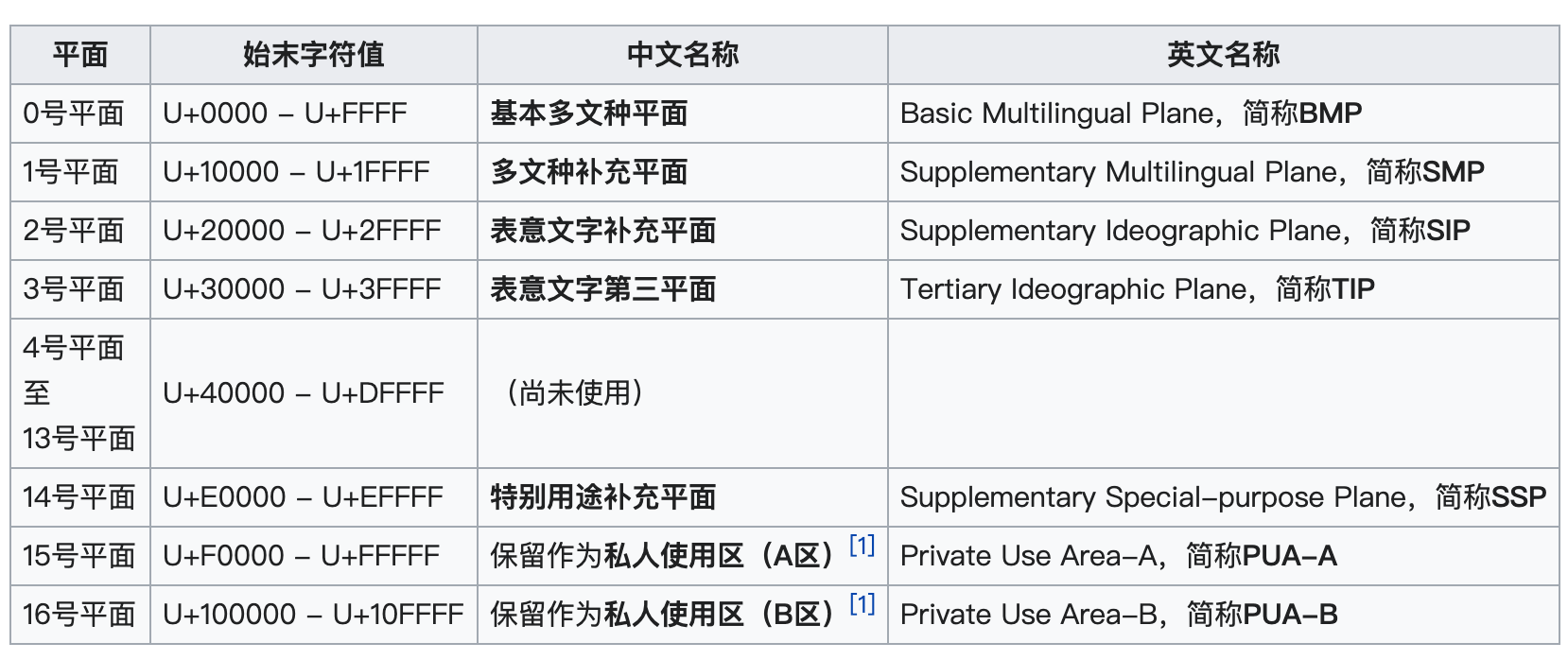
常用的、稳定的字符都放在了0号平面(BMP),编码为0-65535(两个字节),常用的汉字都在这个平面;其他平面一般可统称为辅助平面。
码点转义
基本平面:\u6211 我
辅助平面:\ud834\udf06 𝌆
保留码点
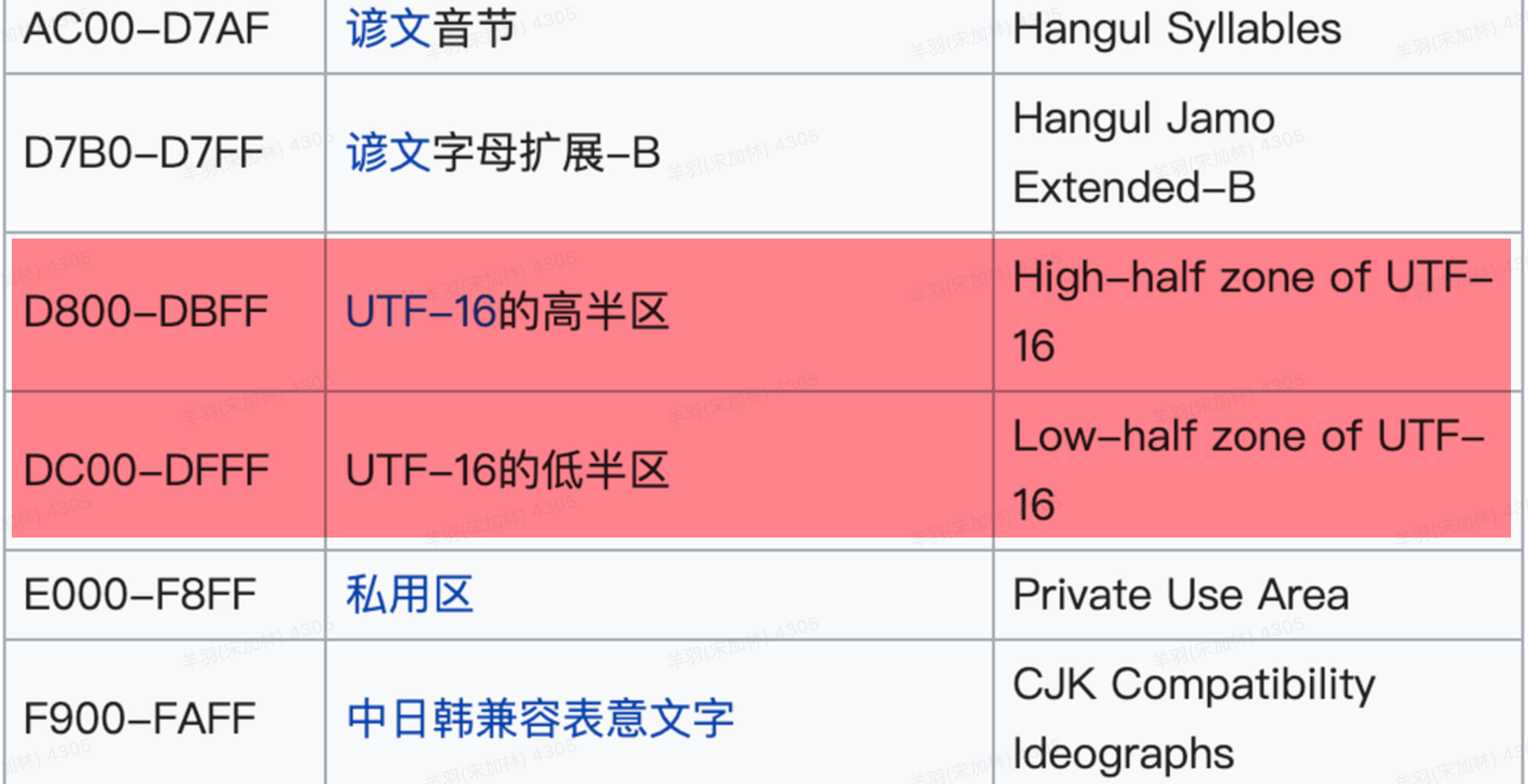
0xD8-0xDB
110110``00`-`110110``11
该码点区间内,二进制前缀固定为110110
0xDC-0xDF
110111``00`-`110111``11
该码点区间内,二进制前缀固定为110111
零宽字符
属于显示控制字符,类似回车字符。特殊之处在于显示时没有宽度
U+200B: 零宽度空格符 (zero-width space) ,用于较长单词的换行分隔U+200C: 零宽度断字符 (zero-width non-joiner) 用于阿拉伯文,德文,印度语系等文字中,阻止会发生连字的字符间的连字效果U+200D: 零宽度连字符 (zero-width joiner) 用于阿拉伯文与印度语系等文字中,使不会发生连字的字符间产生连字效果U+200E: 左至右符 (left-to-right mark) 用于在混合文字方向的多种语言文本中(例:混合左至右书写的英语与右至左书写的希伯来语),规定排版文字书写方向为左至右U+200F:右至左符 (right-to-left mark) 用于在混合文字方向的多种语言文本中,规定排版文字书写方向为右至左U+FEFF:零宽度非断空格符 (zero width no-break space) 用于阻止特定位置的换行分隔
在日常工作中可用于数据加密、数字水印、反爬投毒。
数据加密
数据加密小工具:https://yuanfux.github.io/zero-width-web/
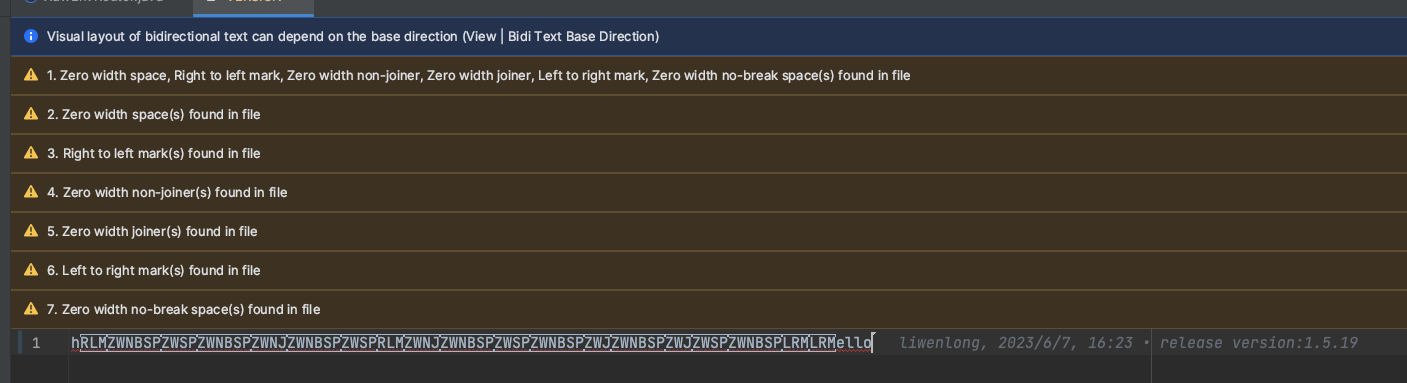
IDEA识别
IDEA中可安装如下插件,识别、警告零宽字符,避免意外复制的零宽字符导致的疑难杂症T_T
UTF
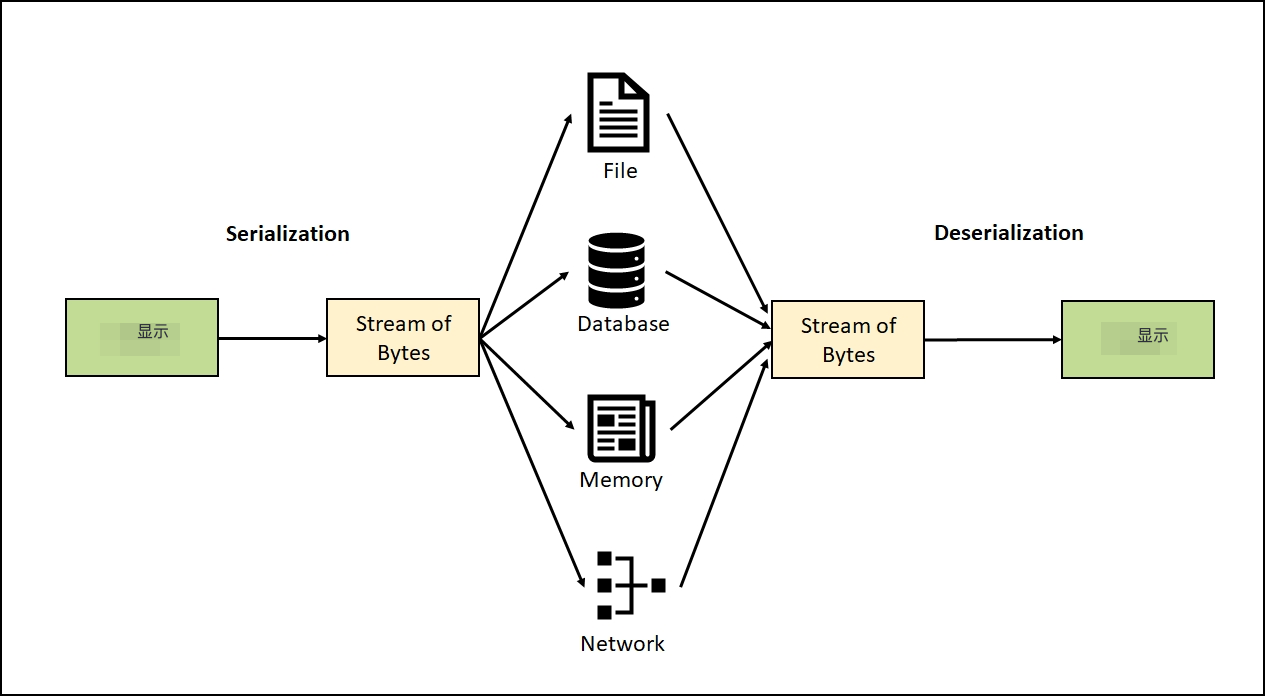
UTF是Unicode的编码、或者说序列化,是特定领域、场景的序列化,是对21bit的正整数做序列化。
和RPC场景下的序列化同理,相关认知、经验可以迁移、借鉴。
核心需要考虑的都是序列化的性能开销、序列化产物的空间开销、粘包/拆包
UTF32
定长编码,无需考虑解码时识别字符边界,按4字节读字符就欧了
序列化产物的单位是32bit(4个字节)。
因为4个字节能表达的编码容量是42亿,远大于unicode 114万。所以每个Unicode都最多会被序列化成4个字节。
这种编码方式没啥花头,就是把0-114万数字编码成一个普通的4字节数字就好了。
优点
简单粗暴,序列化、反序列化代码的开发成本、理解成本都比较低
缺点
空间利用率低,空间利用率都不足2 / 3,这样会浪费很多存储空间,对于网络传输也是一种负担。
0x10ffff是Unicode最大码点。0x10=16,标识第16平面,0xfffff表示16平面内最大的字符码点
UTF16
变长编码,存在两种可能的编码长度,通过固定bit前缀识别、区分
对于基本平面的码点使用两个字节进行编码,对于扩展平面的码点使用四个字节进行编码。
但是这样的话就会有一个问题,计算机在解析的时候怎么知道一个扩展字符是表示一个字符还是表示两个字符?
答案是:代码对(surrogate pairs)
基本平面保留了两段代码点,不表示任何字符,这两段字符就是代码对;
两字节一组,一对代码对就是四字节,一个高位代理(迁到代理)和一个低位代理组成一个代理对。
如下图,BMP字符使用两字节编码,拓展平面字符使用4字节编码:

辅助平面有 16*65536个字符,一共需要20bit来表达。
将20bit对半分,前10bit放到基本平面如下段:

后10bit放到基本平面如下段:


具体规则
- 代码点减去
0x010000,得到一个0x000000 - 0x0fffff(最多20位)的数字。 - 对于不足20位的左边填0,补充为20位,然后均分为两份(
yyyyyyyyyyxxxxxxxxxx) - 高位的(前面的)10位
+D800(110110yyyyyyyyyy)得到第一个码元或者代理对 - 低位的(后面的)10位
+DC00(110111xxxxxxxxxx)得到第二个码元或者代理对。
这样就得到两个码元或者代理对,在解析的时候按照相反的规则进行解析,代理对必须是成对出现,如果解析的时候不是成对出现说明编码有问题,解析失败。
实际案例
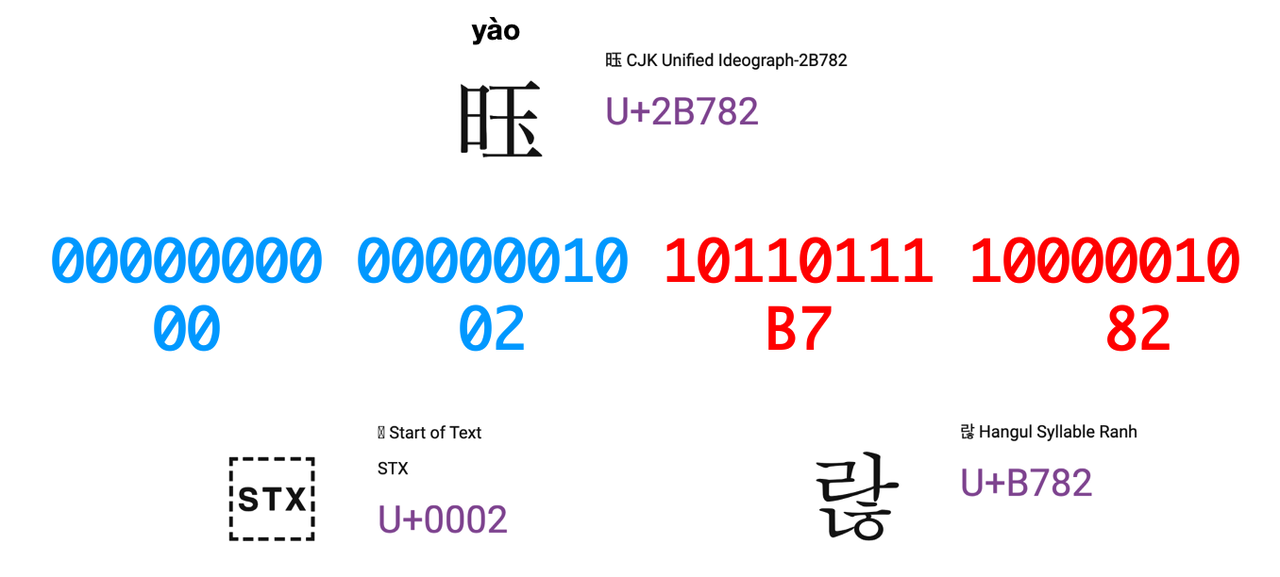
【𫞂】字的unicode码点为:U+2B782
- 减去
0x010000,剩余20bit,不足20位补0到20位
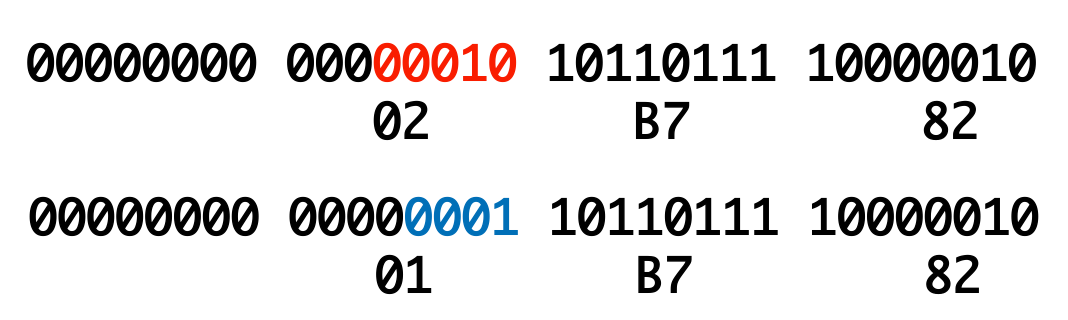
- 高位的(前面的)10位
+D800

- 低位的(后面的)10位
+DC00

- 两部分合并起来,就得到了【𫞂】UTF16编码表示:
0xD86DDF82

UTF8
变长编码,需要通过低成本的方法在编码时,提示字符边界,以便解码时能按边界识别单个字符的编码数组

分为两部分,字符的第一字节算第一部分,剩下的其他字节算第二部分;
第一部分标志当前字符使用几个进行编码,0开头表示是单字节字符,其他情况下看是几个1开头,有几个1当前字符就采用几个字节编码;
第二部分就是比较固定,10开头,后面补上未表示完的位。
通过字符编码的首字节可以得到当前字符编码的字节流长度
Java
在Java中,char是一个基本数据类型,用于表示Unicode字符。它在内存中使用UTF-16编码表示字符,占用两个字节的存储空间。
char取值范围是从\u0000(即0)到\uFFFF(即65535)。由于Java使用Unicode编码来表示字符,所以char类型可以表示几乎所有字符,包括字母、数字、标点符号、特殊字符等。
字符数和码点数
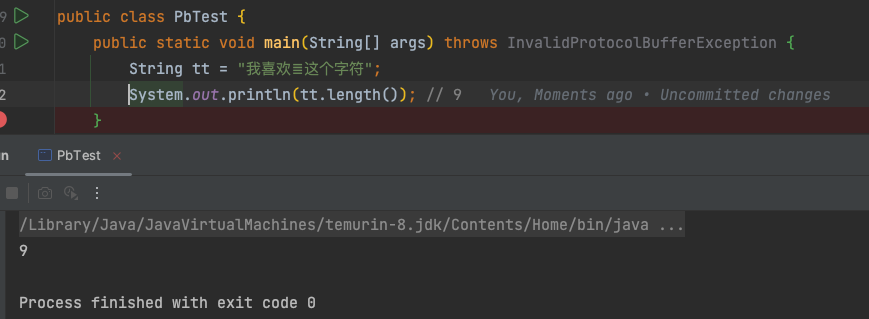
【𝌆】字符的Unicode码点为:\ud834\udf06
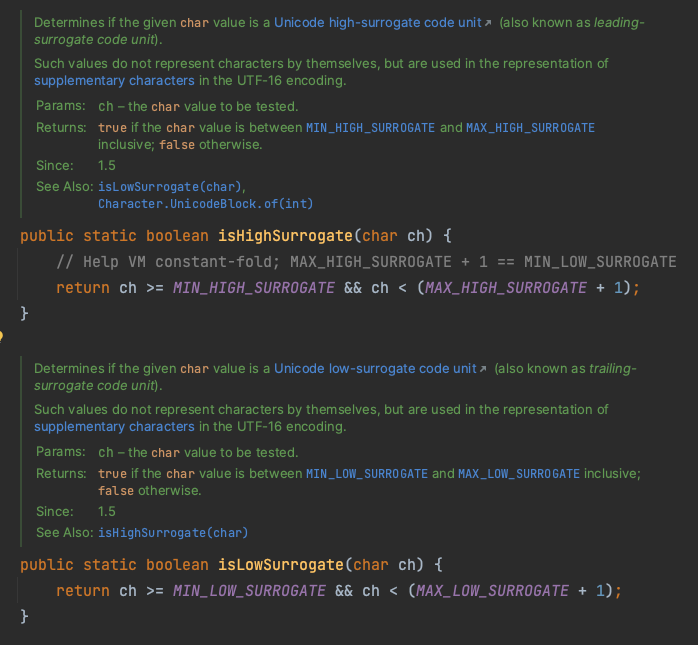
代理对识别
java.lang.Character#isHighSurrogate

String.getBytes(“UTF-8”)
JVM内部用UTF16存储字符串,也就是说,内存上的String是UTF16编码的。
我们常用的String.getBytes("UTF-8")会将字符串先按UTF16解码,然后再按UTF8编码得到字节流。
一次调用产生了两次编解码动作,而编解码动作会大量消耗CPU。
因此,如果字符串较长、包含辅助平面字符(比如emoji、生僻汉字),在String.getBytes("UTF-8")会有较大开销。日常编码过程中需要稍加小心~
参考
这次彻底搞懂Unicode编码和UTF-8、UTF-16和UTF-32 - 掘金
https://lunawen.com/basics/20201129-luna-tech-unicode-plane/
