概述
近一段时间由于工作涉及到编程式的集成、驱动Git,不得不对Git的一些原理进行了一些探究。考虑到Git是SCM领域事实上的垄断者,那么我的探究对于其他人肯定也有重要的参考意义。因此,本文希望整理一下相关的内容抛砖引玉的带大家了解下Git文件存储原理。
Git仓库布局
Git仓库在文件系统上呈现的就是一个普通的目录,但是目录下有一个【Git Database】,这个【Git Database】以隐藏文件的形式放在Git仓库根目录下。
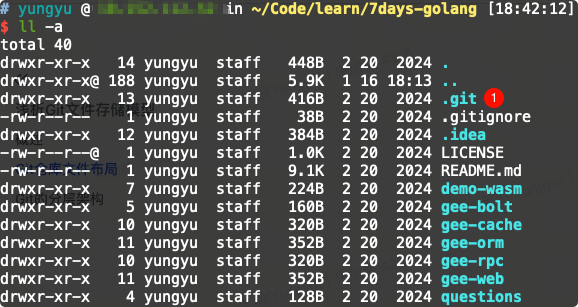
.git目录维护了仓库中文件的版本历史和其他用于分支/引用管理的元数据。只要该目录是完整的,其他文件都可以被恢复。我们常用的git clone命令,本质也就是把这目录从服务器下载到本地。
├── branches 不这么重要,暂不用管
├── config git配置信息,包括用户名,email,remote repository的地址,本地branch和remote branch的follow关系
├── description 该git库的描述信息,如果使用了GitWeb的话,该描述信息将会被显示在该repo的页面上
├── HEAD 工作目录当前状态对应的commit,一般来说是当前branch的head,HEAD也可以通过git checkout 命令被直接设置到一个特定的commit上,这种情况被称之为 detached HEAD
├── hooks 钩子程序,可以被用于在执行git命令时自动执行一些特定操作,例如加入changeid
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── prepare-commit-msg.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ └── update.sample
├── info 不这么重要,暂不用管
│ └── exclude
├── objects 保存git对象的目录,包括三类对象commit,tag, tree和blob
│ ├── info
│ └── pack
└── refs 保存branch和tag对应的commit
├── heads branch对应的commit
└── tags tag对应的commit
Git键值存储
为了实现代码版本管理,Git首先实现了一个基于文件系统的Key-Value数据库,也就是.git/objects目录。
当向该键值数据库写入数据时,按如下算法生成一个数据指纹(40个字符长度的SHA1摘要):
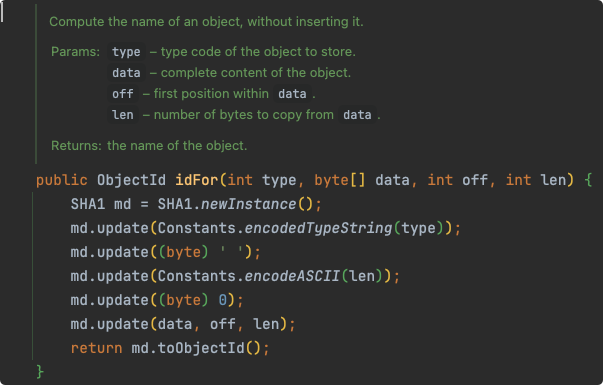
org.eclipse.jgit.lib.ObjectInserter#idFor(int, byte[], int, int)
type限定了数据类型,Git存储层支持有限的数据类型,后面会介绍。
Git管理的所有文件都以Key-Value的形式存放到上述Key-Value数据库中,后续可以用文件Key来引用文件,就像C语言中的指针、Java语言中的引用,这是Git管理文件版本的基础。
这个Key(SHA1)在Git中叫【引用(Reference)】。
Git对象
上文提到Key-Value数据库中存储的数据(Value)有数据类型,下面介绍下Git文件系统中的4中文件类型。
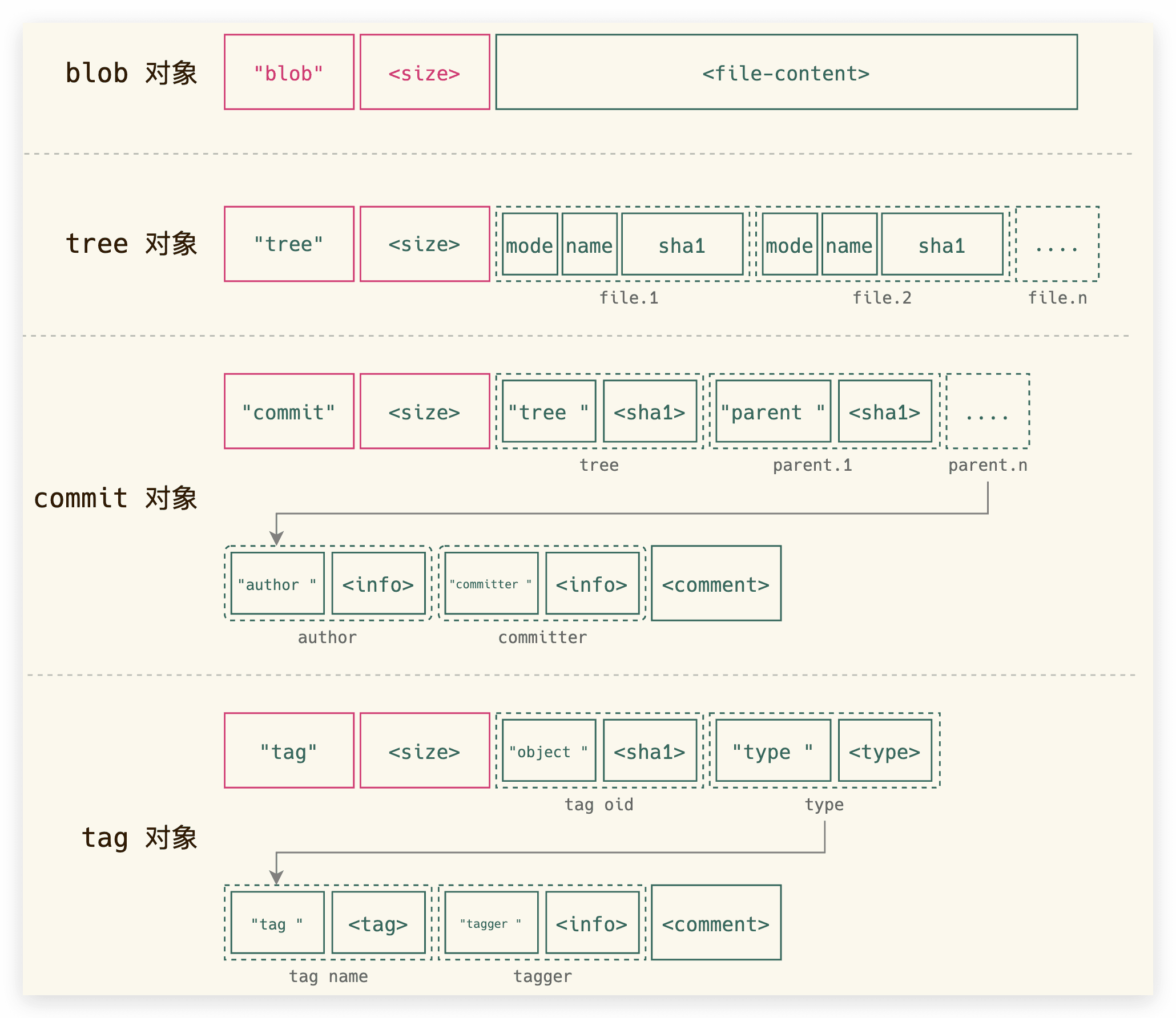
1. Blob类型
每个blob(Binary Large Object)代表一个(版本的)文件,blob只包含文件的二进制数据(Payload),而忽略文件的其他元数据,如名字、路径、格式等。
这个类型的数据,是叶子节点,不会再引用其他类型的对象。
2. Tree类型
每个tree代表了一个目录的信息,包含了此目录下的blobs,子目录(对应于子trees),文件名、路径等元数据。因此,对于有子目录的目录,git相当于存储了嵌套的trees。
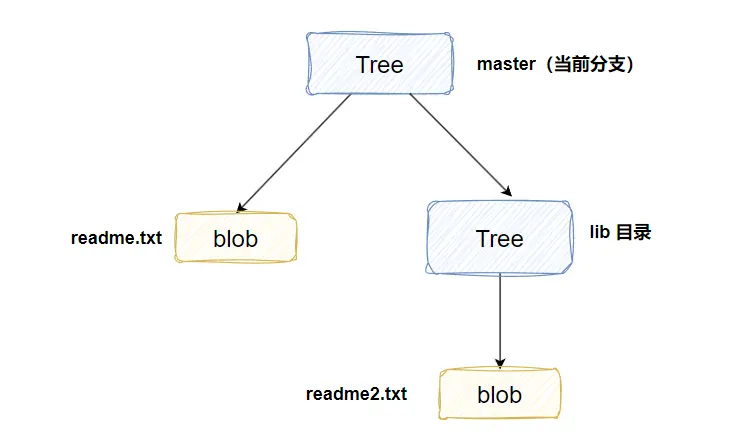
Tree对象是一个逻辑上的HashTable,Key是文件相对仓库根目录的路径,Value是路径对应文件实体和它的元信息(权限)。这个实体可能是一个文件,也可能是一个目录。如果是一个文件,那就直接引用文件Blob对象在数据库的引用(SHA1);如果是目录,那就递归的引用另一个Tree对象在数据库的引用(SHA1)。
3. Commit类型
每个commit记录了提交一个更新的所有元数据,如指向的tree,父commit,作者、提交者、提交日期、提交日志等。每次提交都指向一个tree对象,记录了当次提交时的目录信息。一个commit可以有多个(至少一个)父commits。
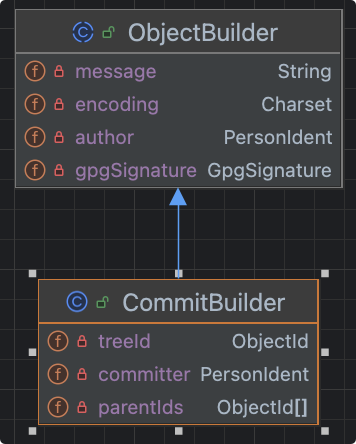
org.eclipse.jgit.lib.CommitBuilder
注意,commit对象持有父提交的引用哦!而且还可以有多个父提交(是个数组)。我们做分支代码合并时产生的合并提交,就会有2个父提交。
4. Tag类型
tag用于给某个上述类型的对象指配一个便于开发者记忆的名字, 通常用于某次commit。
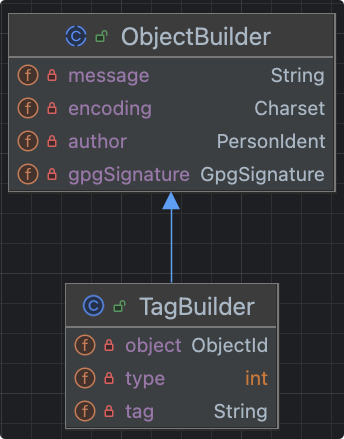
org.eclipse.jgit.lib.TagBuilder
tag对象有自己的注释(message),同时持有一个引用,指向一个commit对象。
-
Git对象编排
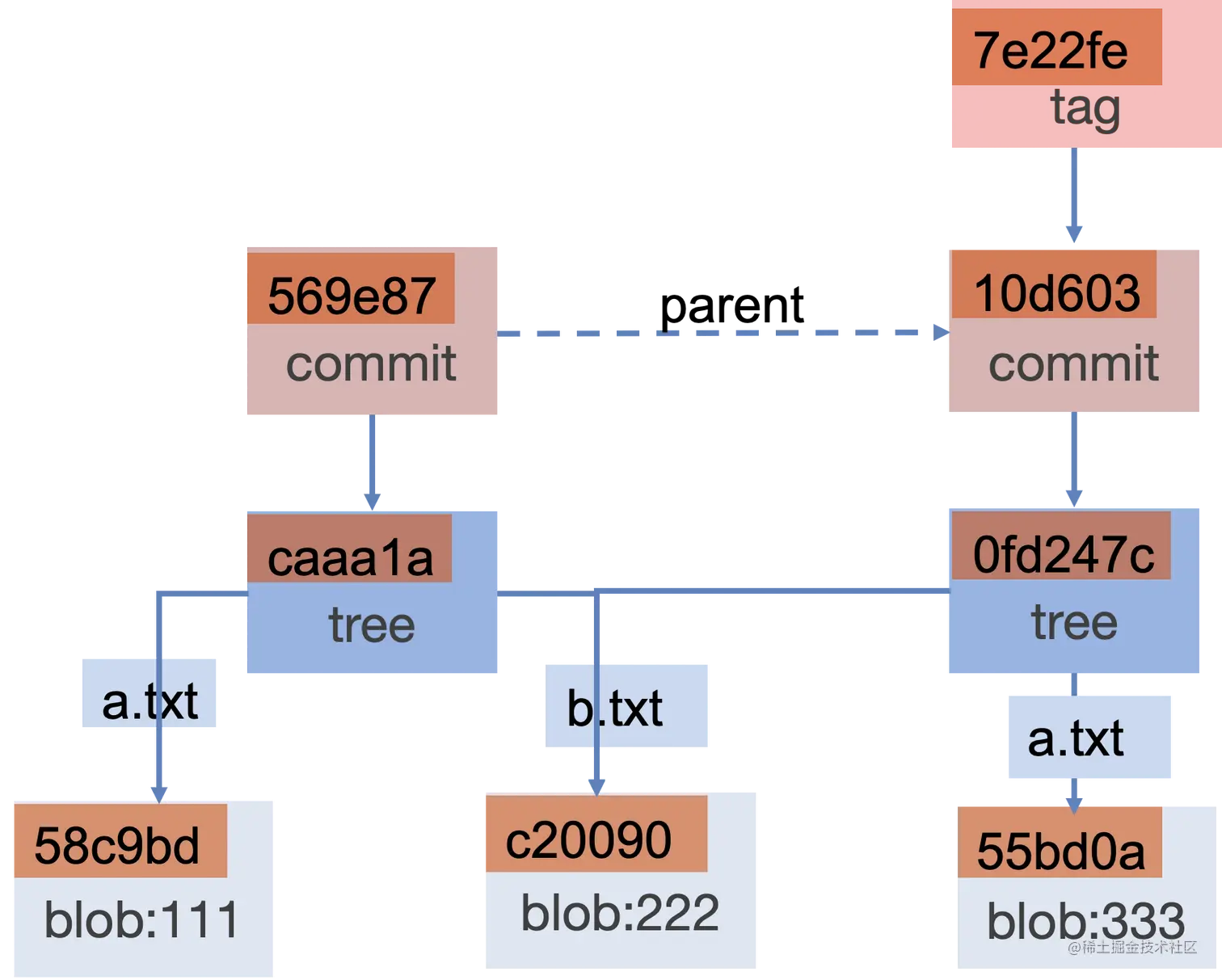
b.txt在两个提交中没有差异,所以复用了同一个blob引用。
Git暂存区
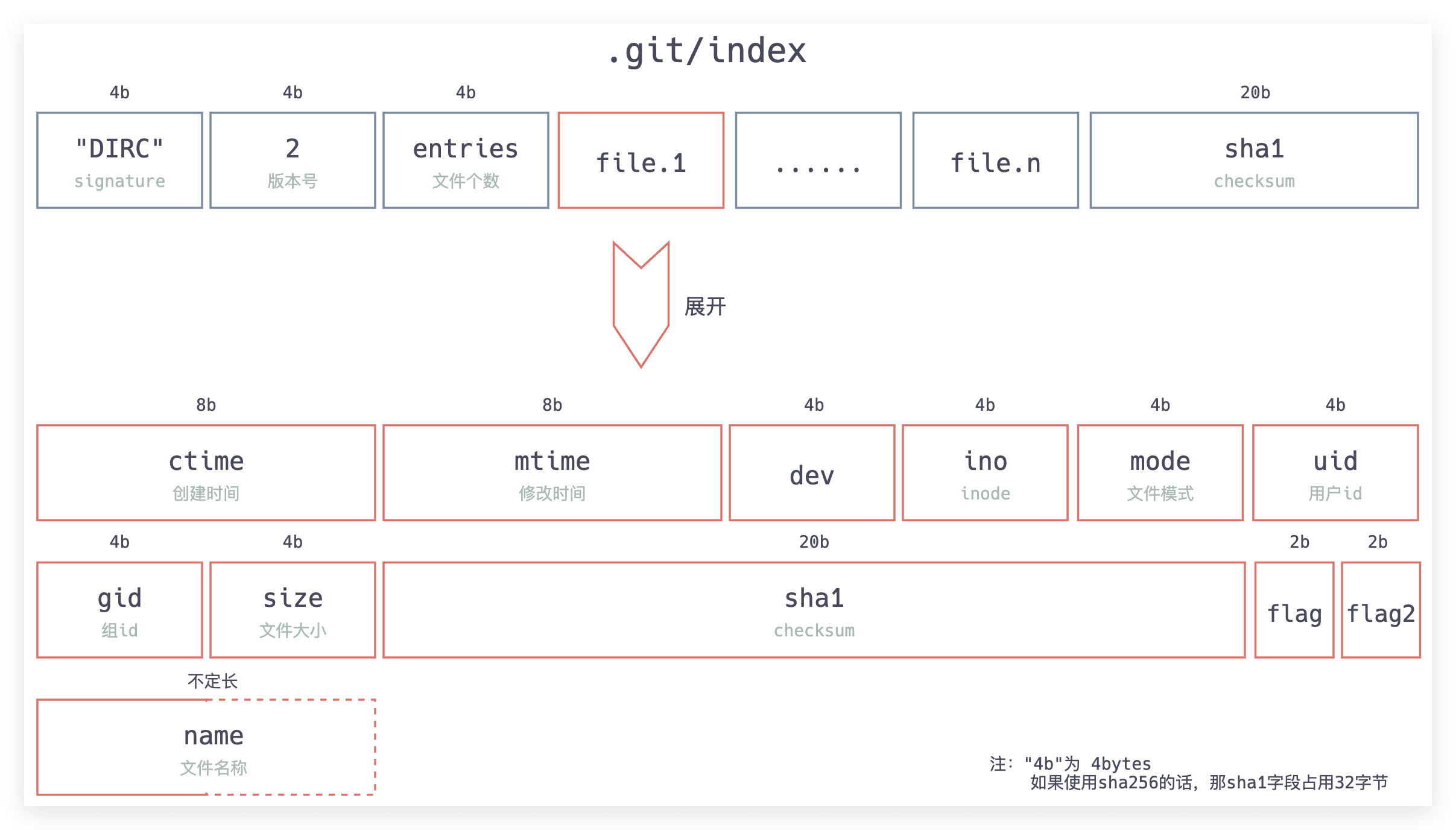
Git暂存区是一个二进制文件,文件路径为.git/index。
该文件宏观结构和Tree对象相似,是一个HashTable,Key为文件全名,Value为文件的引用和元信息。但是该文件不会嵌套,Git仓库中的所有文件会递归的平铺到该文件中。
该文件有两个作用:
- 【正向】将工作区文件状态转换成Tree对象,进而可以创建Commit对象。
- 【逆向】将Commit对象中的Tree对象展开,用于恢复、重置工作区。
因此,我们创建提交的第一步是 git add。文件变更进入暂存区后,再使用git commit基于index文件创建Tree对象、进一步构造Commit对象。
Git分支
我们总听人说Git的分支很轻量,那到底怎么个轻量法呢?其实可以认为,Git分支就是Commit对象的一个友好、易读的别名而已。
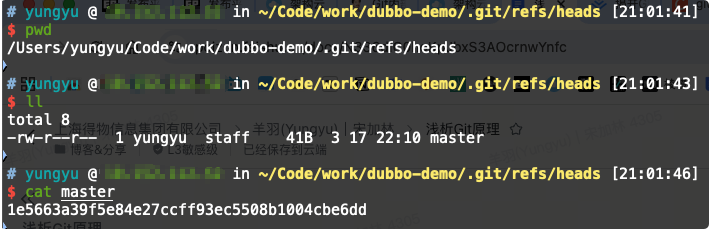
可以看到,master分支就是.git/refs/heads目录下的一个文件,文件的内容是一个引用。这个引用指向一个Commit对象。很轻量吧~
我们git commit时,需要基于分支当前最新的commit来创建子commit,那么当前分支这个状态维护在哪里呢?
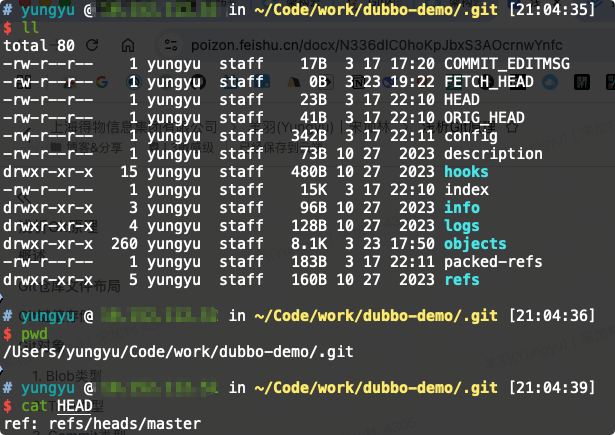
就在.git/HEAD文件里~
总结
本文泛泛而谈的介绍了下Git的文件存储。
