Protobuf编解码原理和实践
概述
数据的本质是一串结构化的二进制流,尤其是当我们需要将数据进行【存储】或者【传输】时,毕竟硬盘和网线都只能透明的处理二进制数据,它们可不会面向对象编程!
现代高级编程语言(如Java、Python、JavaScript等)为我们封装了底层复杂性,开发者日常操作的多是高级数据结构:
- Java中的对象(Object)
- Golang中的结构体(Struct)
- Python中的字典(Dictionary)
- Lua中的表(Table)
当这些高级数据结构需要被存储或传输时,我们就需要一个”翻译官”来填补高级数据结构和二进制流之间的鸿沟。这个”翻译官”需要满足以下核心需求:
- 高效性 :编解码性能必须足够优秀
- 跨平台性 :支持不同语言/平台间的数据互通(如Java序列化的数据能被Python解析)
- 易用性 :开发者友好,学习曲线平缓
如果我们不想自研的话,那市面上符合我们要求的、使用广泛、积极维护的也就只有Protobuf了!
这里的高级,指的是语言抽象程度。Java比C更抽象,C比汇编更抽象。因而Java相对C是高级编程语言、C相对汇编是高级编程语言。
什么是编解码
我们已经知道了,高级语言和底层硬件之间存在数据结构的GAP,这个GAP需要有一个编解码组件来填平。以【网络传输】场景为例,流程大概酱紫:
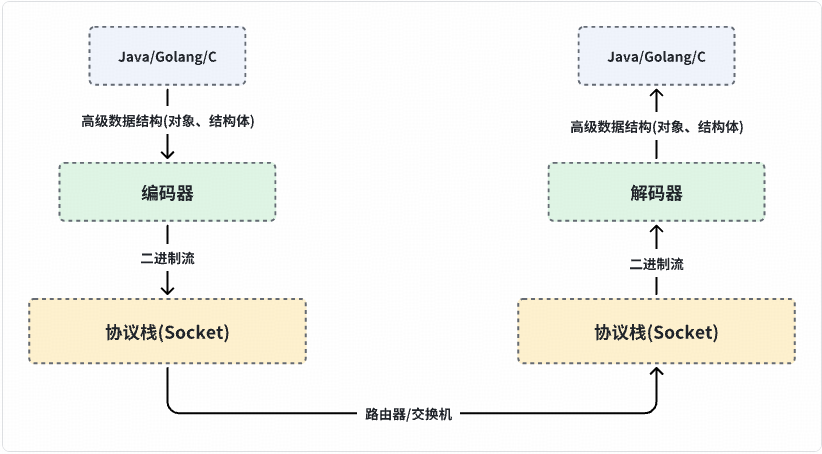
如果不考虑跨语言/跨平台、只考虑同构平台对等读写,那事情其实比较简单。
1. 如果高级语言支持指针
在支持指针操作的语言如C中,开发者可以玩一些”骚操作”:
- 结构体指针和字节缓冲区指针本质都是内存地址
- 编译器会为结构体维护字段偏移量等元信息
- 通过强制类型转换即可实现内存数据的直接读写
尽管可能会因为编译器版本、编译器参数产生bug,但是在特定场景下也不是不能用。
在计算机领域,任何走捷径获得的性能提升,最终都可能以牺牲稳定性和可维护性为代价。
1. 指针解码
我们可以将一个从网络或硬盘中读取来的内存强转成一个结构体来进行结构化的内存读写。
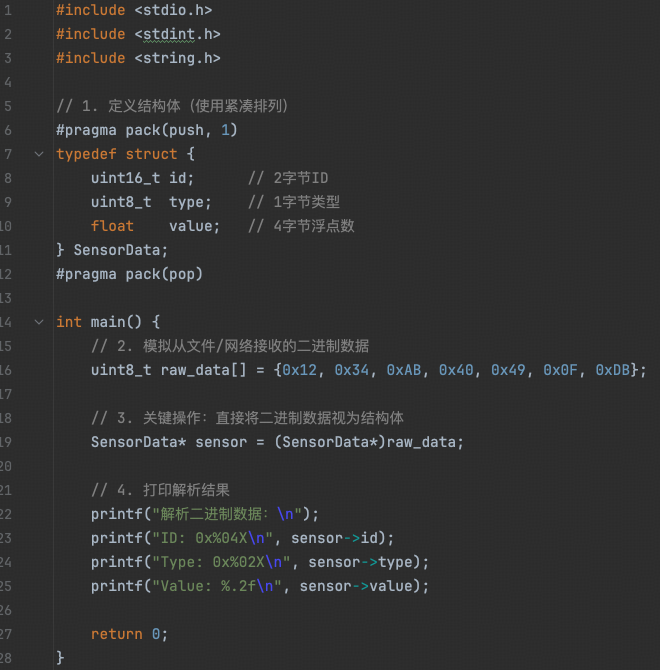
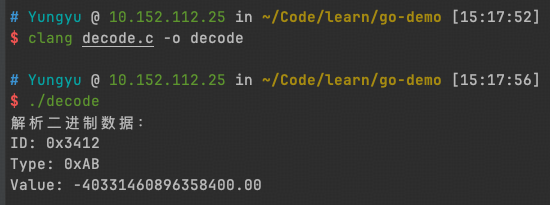
2. 指针编码
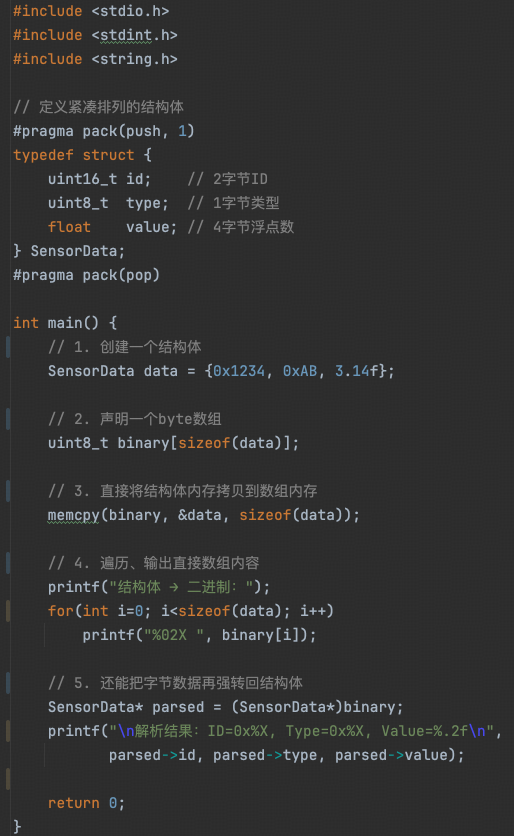
2. 如果高级语言不支持指针
在自动内存管理的高级语言(如Java、Python等)中,情况则大不相同:
这些语言通过以下设计剥夺了直接内存操作的能力:
- 引用替代指针 :只暴露对象引用而非真实内存地址
- 强类型系统 :禁止任意的类型转换和内存解释
- 安全沙箱 :防止直接访问底层内存空间
当然了,好像高版本Java开始逐步的提供直接操作内存的LowLevel API,如:JEP 454: Foreign Function & Memory API
那如果要实现一个通用的编解码器,就只能【反射】了。
- 运行时获取类型信息
- 动态访问字段值
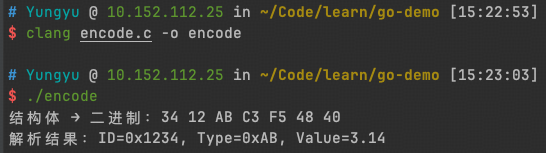
1. 示例数据结构
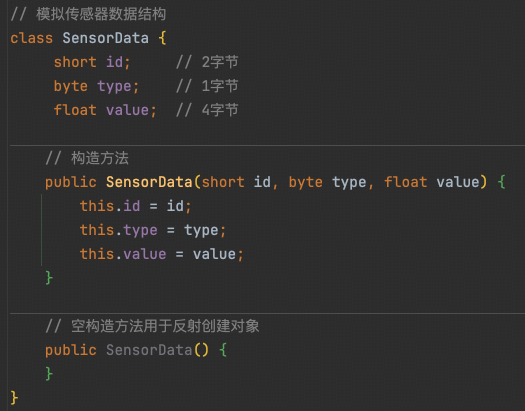
2. 编码逻辑
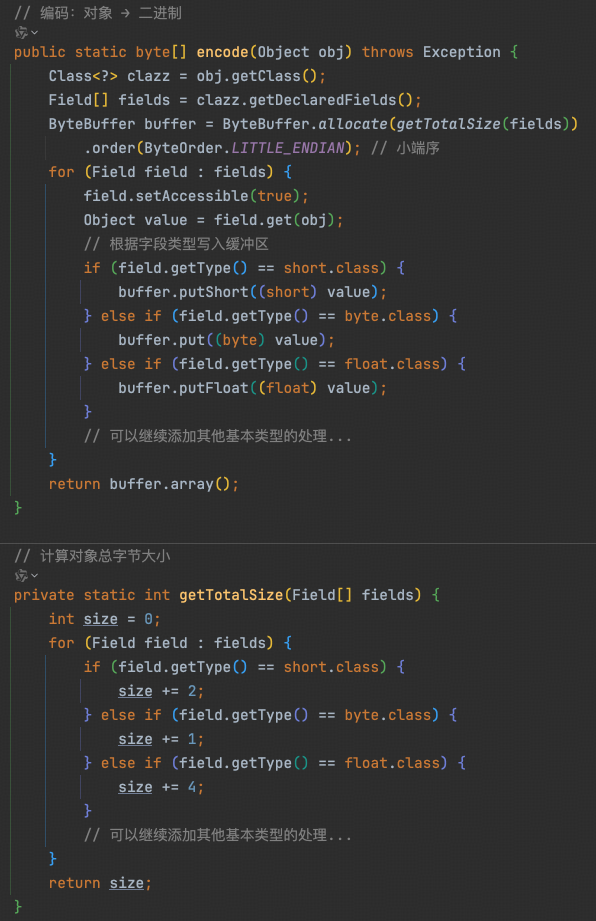
3. 解码逻辑
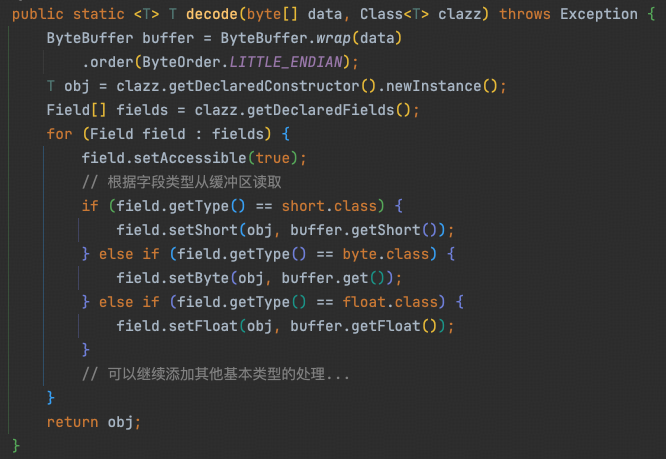
4. 编解码示例

跨平台编解码
尽管同构平台数据编解码从技术上来说不是什么困难的事情,但是我们要考虑到两点:
- 很多的时候,编码、输出数据和解码、消费数据的是不同的系统。比如很可能是Java编码数据,Golang解码数据。
- 反射方式来做数据的读写,性能是比较差的,可以理解为相关代码是解释执行的。
1. 中立数据结构描述
前面的例子里我们分别用C的结构体、Java的类来描述了同一个数据结构:SensorData,它们很难跨平台互通,比如给Golang和Python解码使用。
既然想要多语言、多平台互通,那我们就不能用特定语言的语法来描述数据结构,避免数据结构有平台绑定。
我们干脆从0设计一套语言中立、平台无关的【数据结构描述语言】好了,这个语言没有if/else,没有逻辑,只描述数据结构。
我们就把这个【语言】叫Protobuf吧!
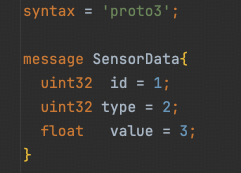
看起来很像各个语言的类、结构体的声明,都是一个大括号来包含所有字段,所以写起来应该很顺手。
为了能兼容各个语言生态,我们取各语言的最大公约数,给他支持如下类型好了:
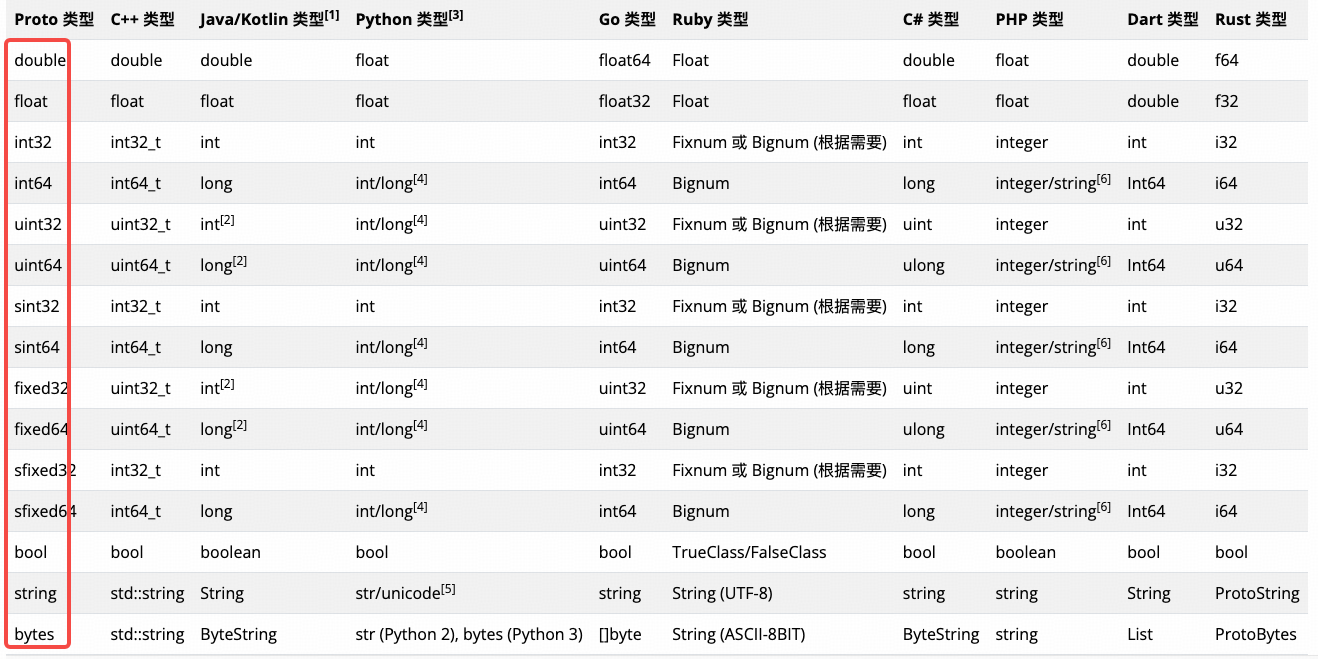
图里的十几种类型是语义化类型,多个语义化类型在存储/传输上可能对应到同一种类型,实际类型不超过8种。
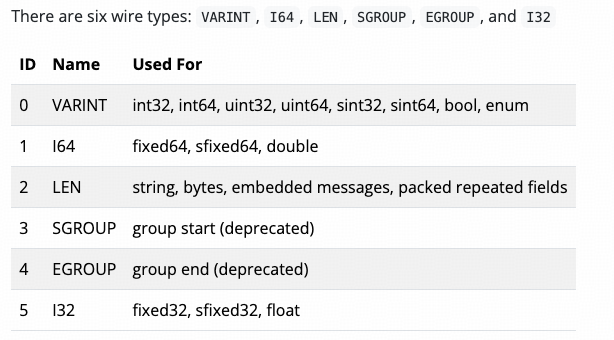
有了这些基础类型,就足够表达出所有业务上需要的复杂的类型了!
2. 二进制数据格式
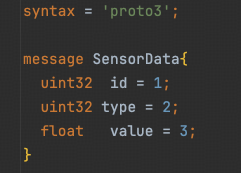
我们希望SensorData的二进制数据结构和具体的语言解耦,有一套独立的结构,那我们约定一下二进制数据布局吧!
- 每个字段都有一个类型和序号。比如id字段的类型是uint32、序号是1。
- 同一个message里,除【列表】类型外,序号不可以重复。
- 每个字段的二进制布局都是【type,index,value】三元组。
那编码后的二进制布局如下:
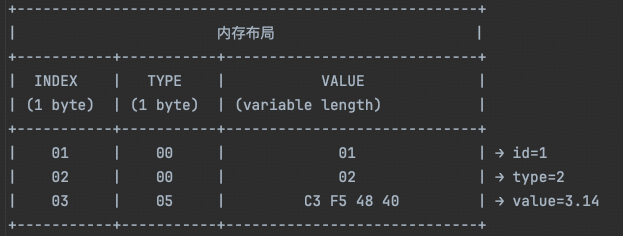
对应的二进制数据流为(假设为小端字节序):
1
01 00 01 02 00 02 03 05 C3 F5 48 40
上面我们说过,我们支持大概十几种数据类型,专门用1个byte来存Type太浪费了!3个bit应该就够了,能表达出8种类型呢!
一个Message里可能有很多字段,所以字段序号Index的容量得高大一些!用4个byte好了,但是其中的低3位用来存Type。
29bit有10亿左右的容量,可以索引足够业务使用的字段数。
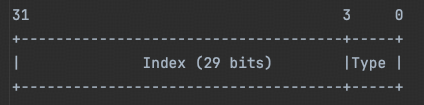
假设我们要存储:
- Type =
0b101(十进制 5,比如表示float类型)。 - Index =
12345(字段序号)。
1. 编码(存储到 4 字节)
- 将
Index左移 3 位,腾出低 3 位给Type:
1
uint32_t encoded = (Index << 3) | Type;
12345 << 3=98760(二进制11000000110101000)。98760 | 5=98765(二进制11000000110101101)。
- 最终存储的 4 字节值(小端序):
1
0xAD 0xC1 0x01 0x00 // 十六进制表示(低位在前)
2. 解码(从 4 字节提取)
- 提取
Type(低 3 位):
1
uint8_t type = encoded & 0b111; // 得到 5
- 提取
Index(右移 3 位):
1
uint32_t index = encoded >> 3; // 得到 12345
3. 桩代码生成
我们已经有了中立的数据结构描述、也约定了编程语言无关的编解码流程。为了实现跨语言通讯,要做的就只是把上述编解码流程,翻译成各个语言的代码了!
以Java为例:
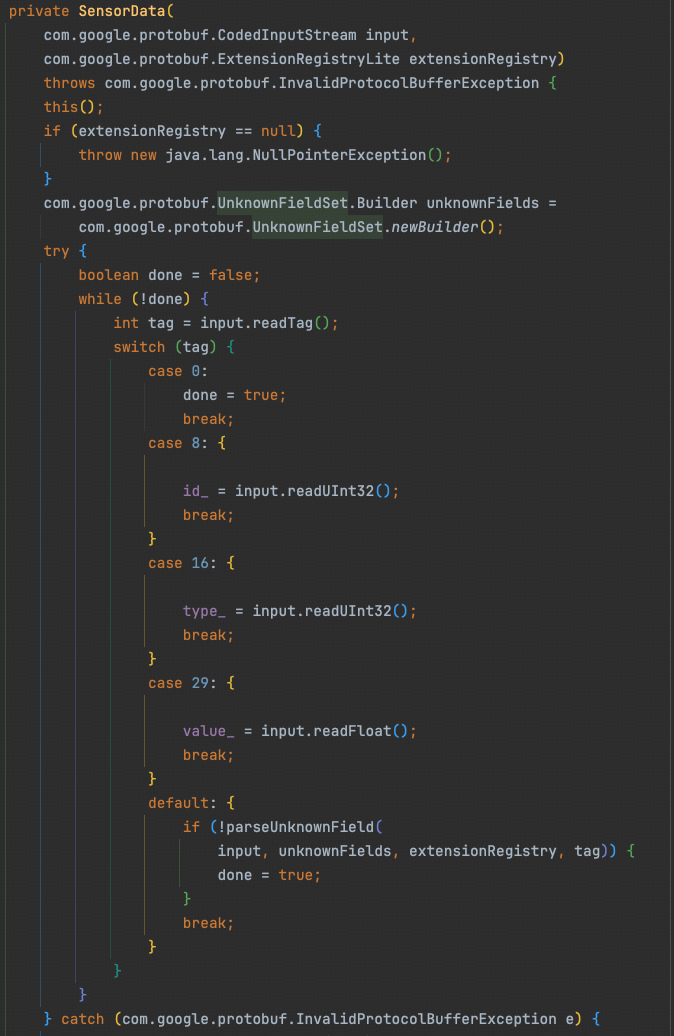
1. 解码(bytes -> object)
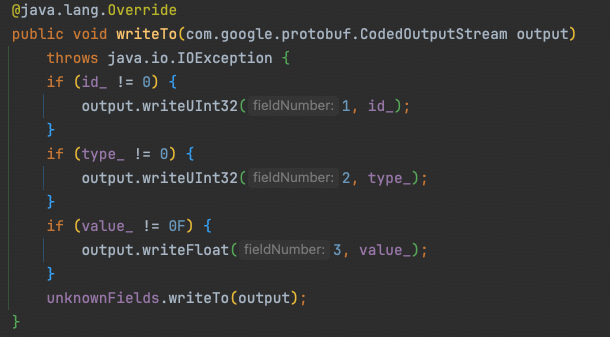
2. 编码(object -> bytes)
3. 总结
因为已经通过数据结构描述文件明确了二进制流数据布局,可以看到object <-> bytes的流程完全没有反射!
Protobuf工具链
上面提到的编解码流程是模板化的,不同的数据结构只是字段序号、字段类型有差异,编解码的流程是相似的!
根本没有必要手写,搞个自动化的工具根据数据结构描述文件来生成就好了!
比如protoc(Protobuf Compiler)。
1. 编译流程

整个编译过程,和经典的代码编译过程非常相似!
- 词法分析 :将
.proto文本拆分为 Token(如message、field、=)。 - 语法分析 :构建 AST(抽象语法树),检查结构合法性(如括号匹配)。
- 语义分析 :验证类型、作用域、依赖关系(如未定义的消息类型)。
- 中间表示 :输出
FileDescriptorProto(Protobuf 的 IR)。 - 代码生成 :内置生成器转换 IR 为目标语言代码。
不同的插件可以生成不同的目标代码,比如java插件、go插件、grpc插件!
2. 插件体系
protoc的插件集成类似MCP(stdin),插件以二进制命令的形式被调用,然后从标准输出流中读取结构化的proto文件信息,进而完成代码生成。
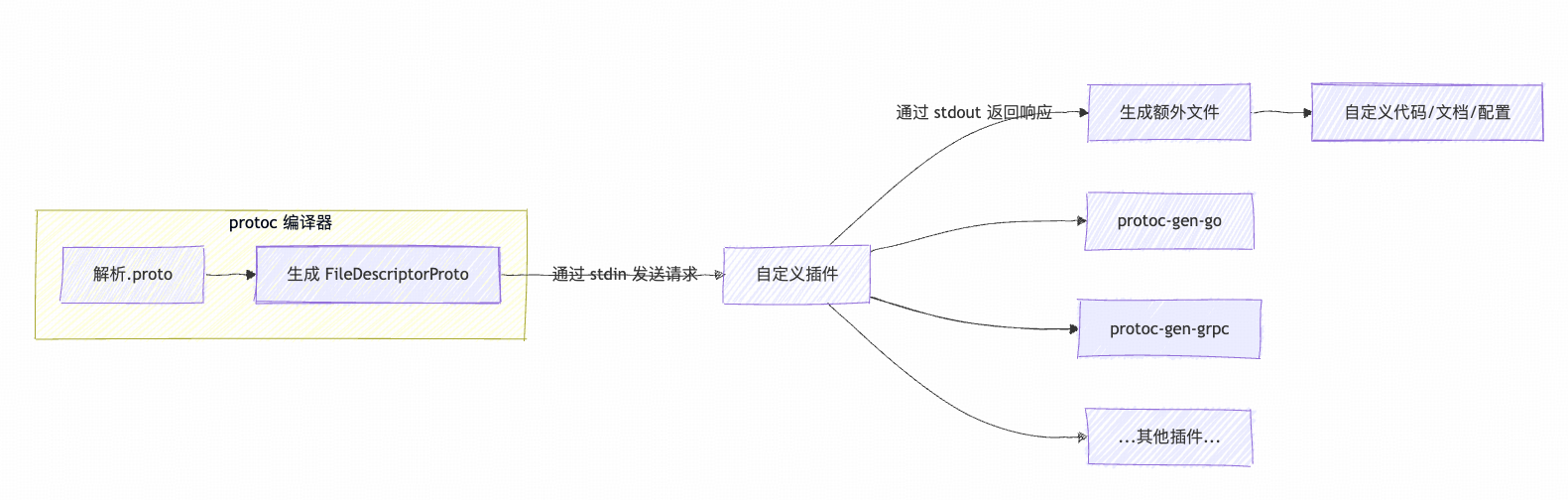
protoc将 解析后的proto文件信息 和参数打包为CodeGeneratorRequest。- 插件通过
stdin接收请求,处理后返回CodeGeneratorResponse。 - 支持并行调用多个插件(如同时生成 Go 代码和 gRPC 桩代码)。
3. 自研插件
比如,我们想要基于proto文件,自动生成Markdown格式的接口文档。那我们要做的就是写段代码,然后解码标准输入流的的输入,然后遍历Message、Service,生成Markdown文件!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
package main
import (
"fmt"
"os"
"strings"
"google.golang.org/protobuf/proto"
"google.golang.org/protobuf/types/descriptorpb"
)
func main() {
// 1. 从 stdin 读取 protoc 请求
data, _ := os.ReadAll(os.Stdin)
req := &descriptorpb.CodeGeneratorRequest{}
proto.Unmarshal(data, req)
// 2. 生成 Markdown 内容
var md strings.Builder
md.WriteString("# Proto API Documentation\n\n")
for _, protoFile := range req.ProtoFile {
md.WriteString(fmt.Sprintf("## File: %s\n", *protoFile.Name))
// 遍历所有 Message
for _, msg := range protoFile.MessageType {
md.WriteString(fmt.Sprintf("### Message: %s\n", *msg.Name))
for _, field := range msg.Field {
md.WriteString(fmt.Sprintf("- `%s %s = %d`\n",
field.Type, *field.Name, *field.Number))
}
md.WriteString("\n")
}
// 遍历所有 Service
for _, svc := range protoFile.Service {
md.WriteString(fmt.Sprintf("### Service: %s\n", *svc.Name))
for _, method := range svc.Method {
md.WriteString(fmt.Sprintf("- RPC `%s(%s) returns (%s)`\n",
*method.Name, *method.InputType, *method.OutputType))
}
}
}
// 3. 返回生成的 Markdown 文件
resp := &descriptorpb.CodeGeneratorResponse{}
resp.File = []*descriptorpb.CodeGeneratorResponse_File{{
Name: proto.String("api_docs.md"),
Content: proto.String(md.String()),
}}
out, _ := proto.Marshal(resp)
os.Stdout.Write(out)
}
最佳实践
以下内容来自官网,为了系统的学习或者记录,我总结到博客里。
1. 1-1-1 最佳实践
“1-1-1”最佳实践建议将定义结构化为每文件一个顶级实体(消息、枚举或扩展),对应一个单一的构建规则。这种方法促进小而模块化的 proto 定义。主要优点包括简化重构、可能降低构建时间以及由于减少传递依赖而减小二进制文件大小。
2. 为已删除的字段预留标签号
当你删除不再使用的字段时,保留其标签号,以防将来有人不小心重新使用它。只需 reserved 2, 3; 即可。不需要指定类型(这样可以减少依赖关系!)。你也可以保留名称以避免重新使用现在已删除的字段名称: reserved "foo", "bar"; 。
3. 不要添加必填字段
不要添加必填字段,而是使用 // required 注释来表述 API 契约。
由于必填字段被认为是有害的,它们在 proto3 中被完全移除。
请将所有字段设为可选或重复。你永远不知道某种消息类型能存在多久,也不知道四年后当它不再逻辑上需要但 proto 仍然要求填写时,有人是否会不得不用空字符串或零来填充你的必填字段。
4. 在枚举中一定要包含一个未指定值
枚举应包含一个默认值作为声明中的第一个值。在 proto2 枚举中添加新值时,旧客户端会将字段视为未设置,并返回默认值或第一个声明的值(如果不存在默认值)。
为了与 proto 枚举保持一致的行为,第一个声明的枚举值应作为默认值,并且应使用标签 0。虽然将默认值声明为具有语义意义的值可能会很诱人,但为了便于随着时间的推移添加新枚举值时协议的演变,通常不要这样做。
所有在容器消息下声明的枚举值都在同一个 C++ 命名空间中,因此请使用枚举名称前缀来避免编译错误。如果不需要跨语言常量,使用 int32 将保留未知值并生成较少的代码。
请注意,proto 枚举要求第一个值为零,并且可以双向转换(反序列化、序列化)未知枚举值。
5. 使用众所周知的公共类型
建议使用以下常见的共享类型。例如,当已经存在合适的常见类型时,请不要在代码中使用 int32 timestamp_seconds_since_epoch 或 int64 timeout_millis !
duration是一个带符号的固定长度时间跨度(例如,42s)。timestamp是一个独立于任何时区或日历的时间点(例如,2017-01-15T01:30:15.01Z)。interval是一个独立于时区或日历的时间间隔(例如,2017-01-15T01:30:15.01Z - 2017-01-16T02:30:15.01Z)。date是一个完整的日历日期(例如,2005-09-19)。month是一年中的月份(例如,四月)。dayofweek是一周中的星期(例如,星期一)。timeofday是一天中的时间(例如,10:42:23)。field_mask是一组符号化的字段路径(例如,f.b.d)。postal_address是一个邮政地址(例如,1600 Amphitheatre Parkway Mountain View, CA 94043 USA)。money是带有货币类型的金额(例如,42 USD)。latlng是一个经纬度对(例如,纬度 37.386051 和经度 -122.083855)。color是 RGBA 颜色空间中的一个颜色。
6. 请将消息类型定义在单独的文件中
在定义.proto 模式时,每个文件中应只包含一个消息、枚举、扩展、服务或 循环依赖组。这使得重构更加容易。当文件被分开时,移动文件比从包含其他消息的文件中提取消息要容易得多。
遵循这一做法还有助于保持.proto 模式文件更小,从而提高可维护性。
如果它们将在项目外部广泛使用,考虑将它们放在一个没有依赖关系的单独文件中。这样,任何人都可以轻松使用这些类型,而不会引入其他.proto 文件的传递依赖。
7. 建议使用 java_outer_classname
每个 proto 模式定义文件应将选项 java_outer_classname 设置为去掉点号后的文件名转换为 TitleCase。例如,文件 student_record_request.proto 应设置为:
1
option java_outer_classname = "StudentRecordRequestProto";
总结
本文没有去展开protobuf的细节,而是步步深入的去说明protobuf的产生背景和使用原理。
protobuf是一个好用的工具,我们一定要掌握它,提升代码的可维护性和性能!